简介(INTRODUCTION)
圆二色光谱(简称CD)是应用最为平常的测定卵白质二级结构的方法,是研究稀溶液中卵白质构象的一种快速、苟简、较准确的方法。它不错在溶液状态下测定,较接近其生理状态。而且测定方法快速方便,对构象变化聪惠。样品对左、右圆偏振光(及正常的光)收受程度不同,产生椭圆偏振光。在深入圆偏振光之前,起初要先容自然光、平面偏振光、椭圆偏振光等宗旨。
自然光:光的一个固有特征是其振动平面与传播标的垂直,在自然光中,自然每一束光的振动平面齐与传播标的垂直,但不同束光之间的振动平面却无关联,可视为平均分拨于垂直于传播标的的整个这个词平面内,且平均来说,任一方进取具有疏导的振幅,这种横振动对称于传播标的的光称为自然光既可将自然光看作念圆柱形的光(下图)。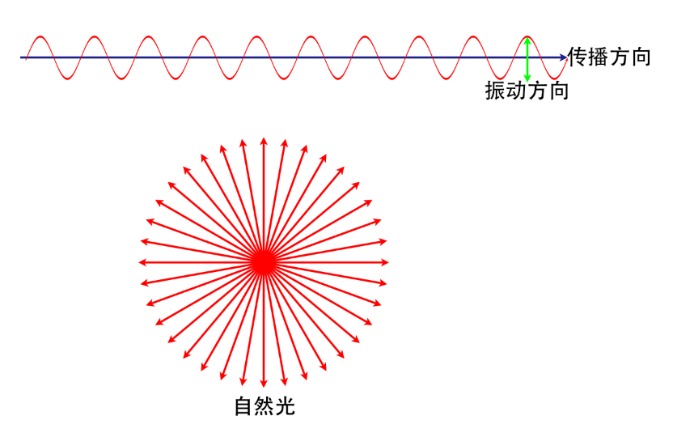
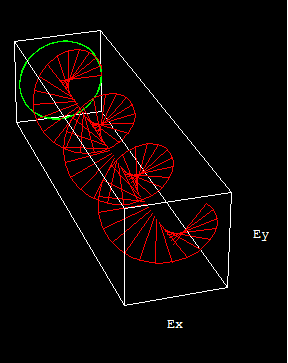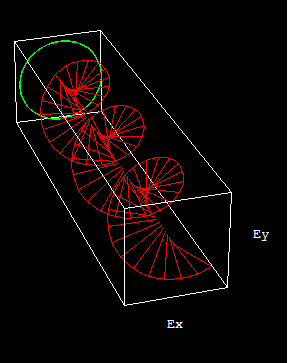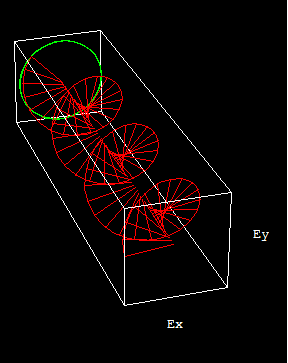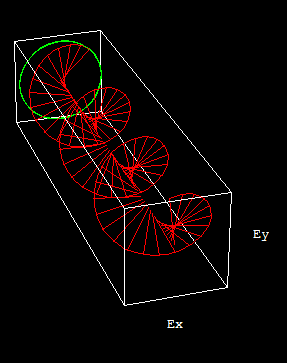
平面偏振光:如果在光的传播方进取光的振动平面在细目的平面内,这种光被称为平面偏振光或线偏振光。
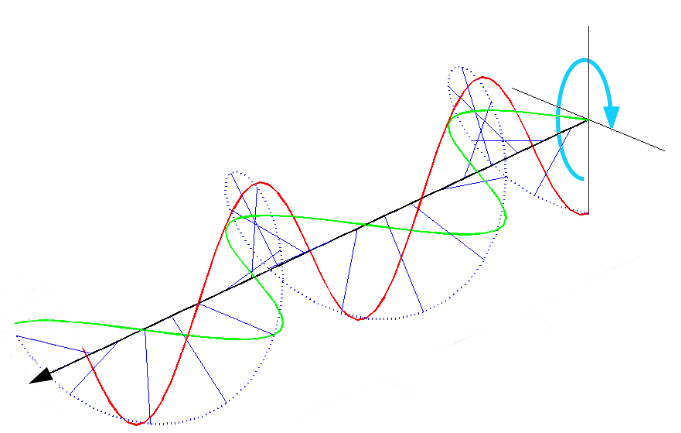
圆偏振光:如果光的振动平面随时期作有规定地改变,即振动平面轨迹在垂直于传播标的的平面上呈圆形或卵形,则称圆偏振光或椭圆偏振光可视为像弹簧一样的光,根据标的又可分左、右旋圆偏振光。因为光革职矢量合成是以圆偏振光可视为传播标的疏导,振动标的相互垂直且相位差恒定为1/2的两平面偏振光叠加后可合成光矢量有规定变化的圆偏振光。圆偏振光的电矢量大小保捏不变,而标的随时期变化,即螺旋前进。
红绿为两束相互垂直,但相位差1/2的两条平面偏振光,蓝色虚线为合成的圆偏振光。
表格:不同光矢量合成着力
类型
频率
振幅
相位
合成着力
平面偏振光
疏导
疏导
差1/2
圆偏振光
摆布圆偏振光
疏导
疏导
疏导
平面偏振光
摆布圆偏振光
疏导
疏导
不同
平面偏振光
摆布圆偏振光
疏导
不同
椭圆偏振光
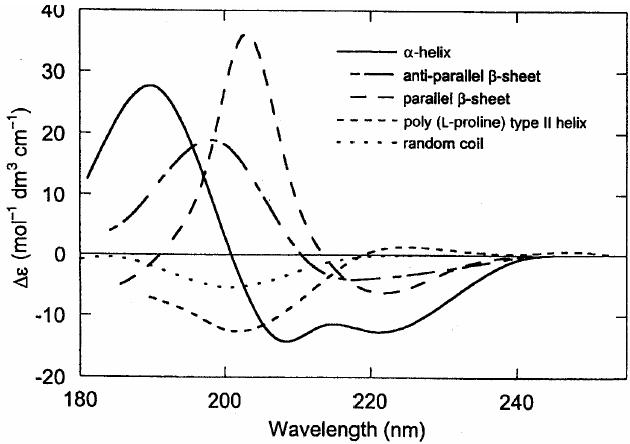
圆二色性基应承趣:卵白质或多肽中的光活性基团有肽键、芳醇基团、二硫键。当平面偏振光通过这些基团时,其对摆布圆偏振光的收受不疏导,形成摆布圆偏振光的振幅不同,合成的圆偏振光变为椭圆偏振光。这就是卵白质的圆二色性。在卵白质分子中,肽链的不同部分可分辨形成α-螺旋、β-折叠、β-转角等特定的立体结构。这些立体结构齐是不对称的。卵白质的肽键在紫外185~240纳米处有光收受,因此它在这一波长鸿沟内有圆二色性。几种不同的卵白质立体结构所推崇的椭圆值波长的变化弧线──圆二色谱是不同的。如下图所示,α-螺旋的谱是双负峰形的,β-折叠是单负峰形的,无规卷曲在波长很短的方位出单峰。卵白质的圆二色谱是它们所含各式立体结构组分的圆二色谱的代数加和弧线。因此用这一波长鸿沟的圆二色谱可研究卵白质中各式立体结构的含量。
专揽圆二色谱考据卵白质褂讪性
广泛实验中需要考据卵白质与小分子结合或者卵白质自己的褂讪性,专揽圆二色谱测定卵白质(与小分子结合)的变温弧线,咱们不错通过筹办其Tm值细目其褂讪性。
材料(MATERIALS)
试剂(REAGENTS)
石英杯清洗剂(仪器中心提供)
缓冲液(BUFFER)
磷酸盐缓冲液,150 mM NaCl
器械(EQUIPMENT)
Chirascan Spectrometer (Applied Photophysics,Leatherhead,UK)、1 mm厚度的石英比色皿
实验格式(PROCEDURE)
1. 准备卵白样品,浓度为0.3~0.5 mg/mL,卵白所在缓冲液为磷酸盐缓冲液;
2. 圆二色谱仪开机后需要充氮气约30 min,再掀开疝气灯。确立扫描波长鸿沟:180 nm~260 nm,重复2次。
3. 先检测仪器褂讪性,平直扫描空气,得到一个鸿沟在0.1隔邻的直线为正常,在检测卵白圆二色谱弧线前分辨检测对应的缓冲液弧线(应该是一条直线);
4. 检测样品二级结构折叠情况:吸取200 μL卵白样品至规格为1 mm厚度的比色皿中,透光不雅察幸免气泡,温度为20 °C,扫描后可得到弧线;
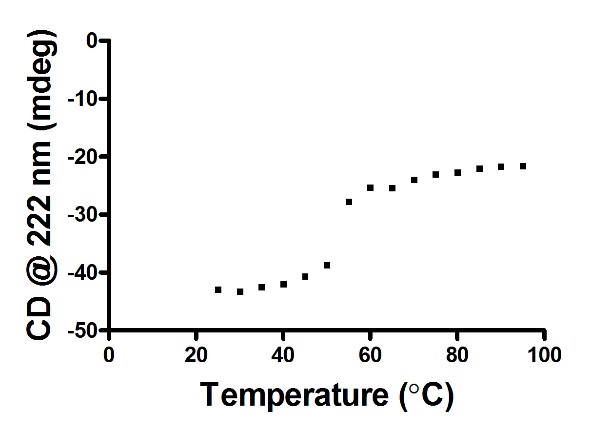
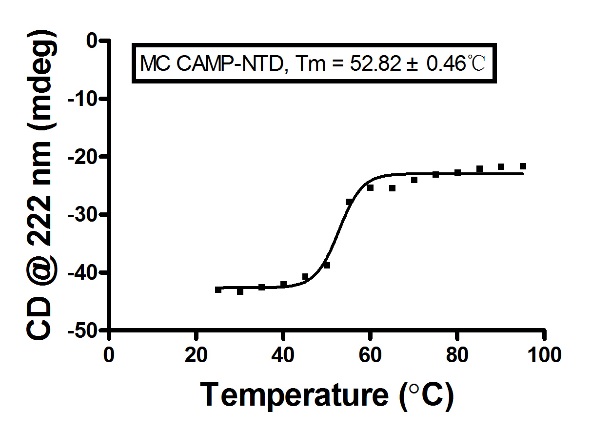
5. 检测卵白质热变性:需要开启冷轮回禁止器。吸取200 μL卵白样品至规格为1 mm厚度的比色皿中,透光不雅察幸免气泡,将温度探伤针插入样品中,温度鸿沟是20 °C~95 °C,每隔5 °C检测一次,每次检测重复2次。根据卵白运行二级结构光谱弧线取220 nm或者222 nm处的数据用GraphPad Prism 5.0作念图,拟合并筹办Tm。
附:数据处理与斥逐
考据Mobiluncus curtisii CAMP-NTD的二级结构偏激热褂讪性。
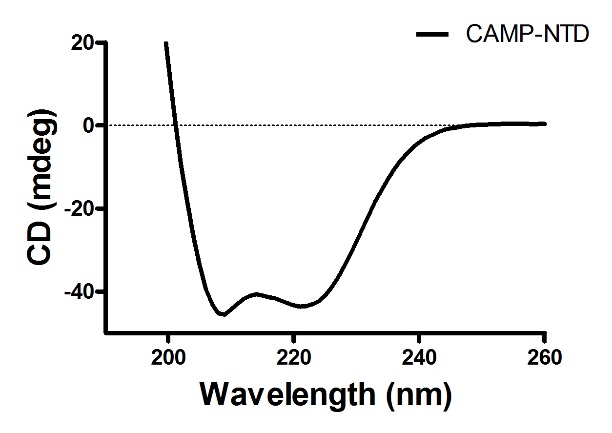
1. NTD的圆二色谱:经如上实验格式取得实验数据,导入Prism中作弧线图,得如下斥逐,为规定的α-螺旋:
2. NTD的热变性弧线:及第EXCEL数据表中222 nm处的数值(为不同温度在222 nm扫描得到的数值)导入Prism中作弧线图,得到如下斥逐:
3. Tm值的筹办:
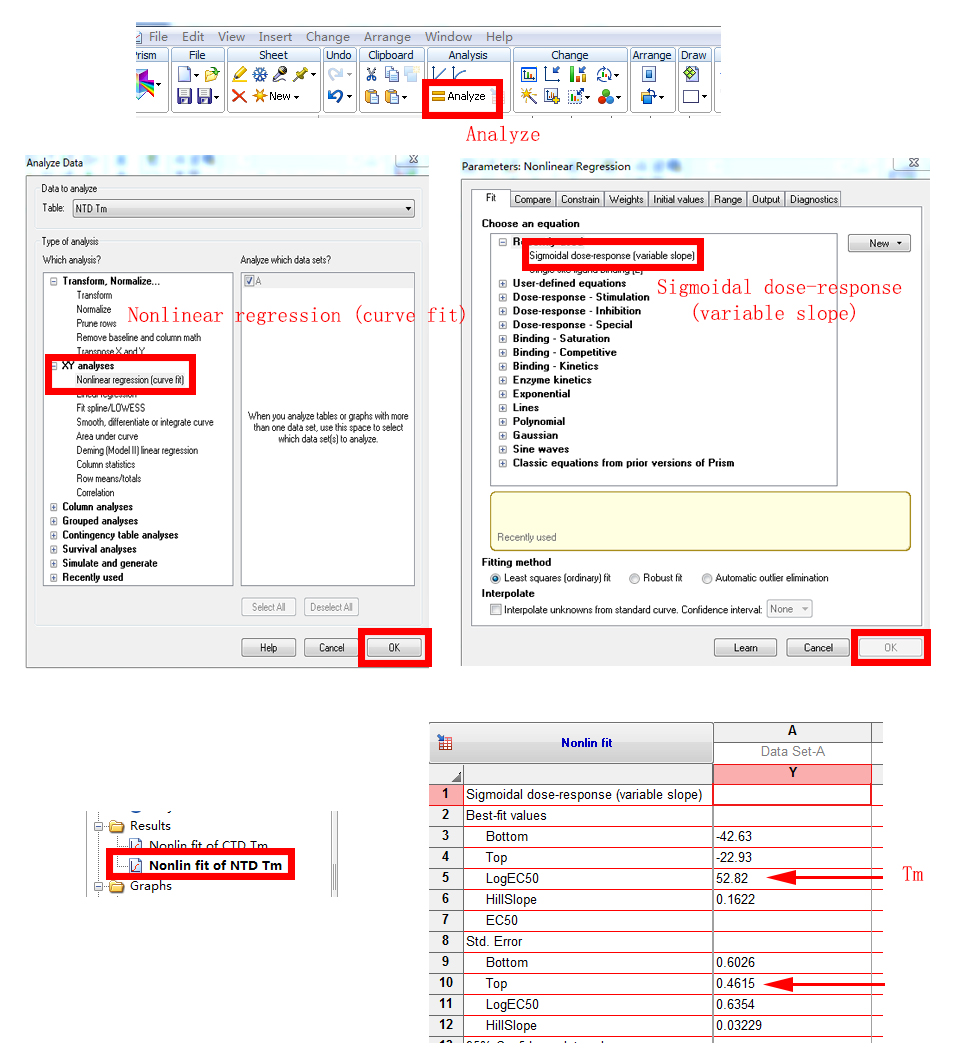
4. Fit后的斥逐,如下图:
针对性建议(TROUBLESHOOTING)
样品要求:
1. 样品必须保捏一定的纯度不含光收受的杂质,溶剂必须在测定波长莫得收受侵犯;样品能完全溶解在溶剂中, 形成均一透明的溶液;
2. 氮气流量的禁止,实验半途要时刻关注氮气是否充足,如不充足需实时更换氮气瓶;
3. 缓冲液、溶剂要求与池子取舍:缓冲液和溶剂在配制溶液前要作念单独的搜检,看是否在测定波长鸿沟内有收受侵犯,看是否形成千里淀和胶状;在卵白质测量中,频繁取舍透明性极好的磷酸盐看成缓冲体系;
4. 样品浓度一般在0.05~0.5 mg/mL,浓度太高杂音太大会影响斥逐;
5. 样品不同,测定的圆二色光谱鸿沟不同,对池子大小(光径)的取舍和浓度的要求也不一样;卵白质CD光谱测量一般在相对较稀的溶液中进行;
6. 保捏石英杯干净透亮,广泛完成卵白热变性检测后石英杯里面会有卵白质粘物,需要用清洗剂浸泡30分钟,再用净水冲洗干净;
7. 用去垢剂洗完石英杯后,需要用70% 酒精进一步清洗。
5.2 小角散射简介(INTRODUCTION)
X光散射工夫是常用的非蹂躏性分析工夫,可用于揭示物资的结构、化学构成以及物感性质。这些工夫是以不雅测X射线穿过样品后的散射强度为基础,根据散射角度、极化度和入射X光波长对实验斥逐进行分析。
散射包括弹性散射和非弹性散射,弹性散射包括小角X射线散射(SAXS)、广角X射线散射(WAXS);非弹性散射包括康普顿散射、共振非弹性X射线散射及X射线拉曼散射。SAXS主要测量散射角2θ接近0° 时的经过样品后的X射线散射强度,而WAXS是测量散射角2θ大于5°。
在旨趣上散射振幅等于电子密度的傅立叶变换乘以一个角度关系的因子。假设样品有好多一样的颗粒构成,每个颗粒里面的电子密度以ρ(r)走漏,最大的维度为Dmax,那么总的散射强度不错写成球坐标时势:,其中γ(r)是密度的自关系函数的球形平均值(吞并个长度,不同标的的平均)。I(s)的极限即为Guinier公式,也就是ln[I(s)] vs s2,这个极限公式在s<的鸿沟内适用,Rg为回旋半径。
SAXS的优点:对样品的要求很低,溶液样品即可,对分子量和浓度莫得要求。由于SAXS在溶液中进行,因此更好地反应生物大分子的真实状态,对原位研究动态过程提供了可能性。
SAXS的症结:得到的信息量很少,要得到三维结构的信息很穷困,只可得到一些比较直快且低分辨率的信息,如生物大分子的大小、时势、某些重要的片断、各个组分之间的空间关系等。对于SAXS来说,分子越大实验越容易,这一丝和晶体学巧合相背。
SAXS数据分析先用RAW软件:
(不错从_install.html免费下载软件并根外传明进行安装)来进行data reduction之后,一般用ATSAS软件包,里面包括好多小软件,根据不同的需要取舍合适的软件。求解大体时势时不错用gnom、damin、gasbor等软件;如果是重建柔性区域不错用credo、corel、crysol等软件;如果是复合物结构重建则需要用massha、sasref、crysol等软件。
每一种软件齐不错在https://www.embl-hamburg.de/biosaxs/software.html上活得对应的manual。
材料(MATERIALS)
试剂(REAGENTS)
60 μL高纯度卵白样品(浓度在1~10 mg/mL鸿沟内、根据分子量、分子量越小浓度需要高一些、分子量越大浓度需要低一些),如果是胞内卵白不错加2~10 mM DTT看成radiation damage保护剂。
10 mL严格对应的buffer
器械(EQUIPMENT)
同步辐照加快器19U2线站
实验格式(PROCEDURE)
Data reduction
1. 将卵白在1~10 mg/mL之间用对应的buffer稀释三种梯度,并放在线站内的样品托盘上。
2. 在线站的软件上确立样品的称号,网罗纪律以及保存旅途。
重要格式:这里需要提神的是,该软件是在linux环境下责任的,因此在样品称号中不得出现空格和/等标记,如果一定要用分割则用“_”下划线标记。还有,如果是在新的文献夹中开始网罗,在Next tube No.上填写“1”,如果是在原本的旅途中接续网罗的话千万不要改动,否则吞并个序号的数据后者会掩盖前者,这就意味着之前网罗的数据需要重新收。
3. 掀开光源,并点击“run”,开始网罗数据,在线站的ALBRA软件上搜检detector网罗的散射光图片是否正常,如果是圆形的光斑那就是正常的,如果边际上有刺头那说明光路有问题,需要找线站的责任主说念主员重新调治光路。
4. 网罗好的数据传到线站中的另一台Windows电脑上,此电脑上一经安装好了RAW、ATSAS瓜分析软件。每一次收数据之前,线站的责任主说念主员会帮咱们调治好光路和确立,并保存一个cfg文献,掀开RAW,先将旅途调治至cfg文献所在的位置,并双击该文献,这样才不错导入本日的参数。
5. 然后将文献过滤成tif文献,每一个样品咱们一般网罗20张数据,取舍某一个样品的20个数据,点击“plot”,此时摆布的窗口会傲气20个弧线况兼正常情况下会简直重复在全部,如果莫得,将不重复的那些数据删除,剩余的数据取舍后点击“average”。平均出来的数据咱们需要自行保存。
6. 一般每一个样品前后齐会测对应的buffer,因此不错取舍前边或者背面紧挨着的数据看成该样品的配景并扣除。将样品和buffer齐进行平均后,在buffer数据摆布点亮“★”,并取舍样品,点击“substract”。此时得到的数据是将配景扣除后的样品隧说念的信息。相通,substract后的数据也需要保存,一般著作中提供的原始数据齐是从substract开始展示,况兼背面的一系列分析也齐是基于这个原始数据来进行的。因此这一步要作念好,否则背面的分析齐不确凿。
7. substract后的数据不错用记事本掀开,里面的数据不错用prism去重新绘图。
Data analysis
1. 掀开ATSAS软件中的“SAS Data Analysis”,将通过data reduction得到的substract数据拖到界面中。
2. 一般比较三种浓度梯度的信号强度,保证s小的方位信号莫得过度的条件下s大的方位信号尽可能少的波动。如果数据重新到尾齐是信号很强的状态,那么这种数据偏artifitial。如果三种浓度梯度信号莫得一个能知足这个条件,不错将高浓度的尾部和低浓度的头部进行merge,方法是通过软件中的“processing”中的“scale”将落魄浓度的数据进行拟合,使两个数据在某一丝有重复,再点击“merge”,这时软件会自动生成一个新的数据,而这数据不错用来背面的进一步分析。
3. 初步分析,一般需要看样品的回旋半径是否是浓度依赖的?Dmax是不是浓度依赖的?
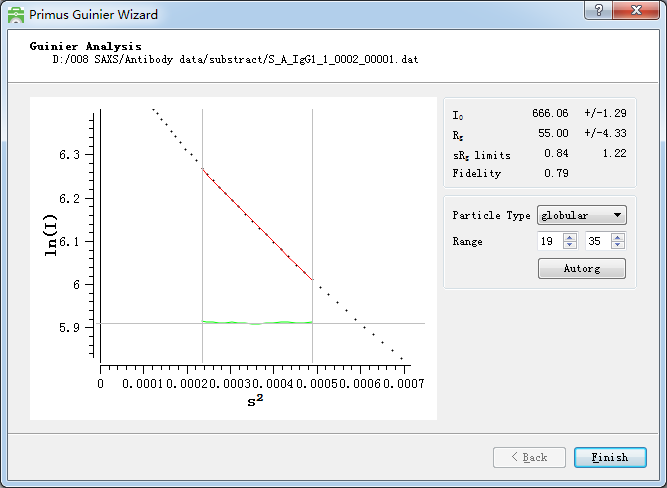

1. 因为回旋半径就跟卵白的等电点一样是样品的固有属性,原则上它不可能跟着样品的浓度的变化而变化。Dmax是样品的最大直径,如果溶液中的样品是一个均匀的介质,那么这个也不会是浓度依赖的。如果Dmax跟着浓度高而变大,那么极有可能是样品有很强的集合才略,这种情况下咱们只可用低浓度的数据。这里放一张回旋半径和对样的分子量的表格,回旋半径和分子量是呈正比的,分子量越大回旋半径也越大。回旋半径不错通过软件中的“radius of gyration”即回旋半径,来进行筹办,这里用到的是guinier公式,因此需要知足,况兼需要让履行的样品弧线尽量和拟合后的线性弧线重复。同期也要保证绿色的弧线的落魄散播是均匀的,幸免多数在上头或者底下。
2. 底下是Dmax的筹办,点击“distance distribution”,会出现如下图。咱们需要关注的是p(r) vs r弧线的尾部需要平缓地往下走,如果是很陡的那种需要东说念主为地在range中改变包括的点的数量来变化。上头的quality是表征这套数据的质地的轨范,自然,这个数值越高越好,但咱们更多照旧要看圆圈中的图形。点的数量不需要太多,如果好的数据不错留好多点,但如果s很大的方位杂音很高的话,不错只留400~500个点,即到s在0.2摆布的数据亦然不错的。点击“finish”后会提醒保存数据,保存后不错用记事本掀开,将里面的数据用prism重新绘图。
Modeling
1. 作念完低级分析后,背面完全是根据实验目的来取舍特定的软件,在SAS Data Analysis中一经整合了dammif、crysol、oligomer、Bodies等常用的软件。其他的软件全部齐不错在ATSAS软件包中能找到,不同的软件在Embl-hamburg网站上齐能找到manual,因此这里用dammif来先容如何建模。
2. 点击“dammif”,取舍“manual”,在筹办Rg中取舍合适的点,在Dmax上参考第11步,也不错在前边把数据记下来,平直在这里输入,点击“next”,直到终末界面上。如果直到该样品的对称性不错取舍,如果不知说念默许是P1对称性。在anisometry上不错取舍是球形照旧长棍形,以及在angular scale上不错取舍是nanometer照旧angstrom级别的,默许齐是unknown。在mode上不错取舍fast或者slow,区别是筹办时期上fast更快,况兼模子中球的数量更少,但轮廓更彰着。如果是slow模式的话,筹办时期很长,模子中球的数量更多,轮廓不彰着。在repetition上不错取舍筹办的轮数,不错自界说筹办几轮,每一轮的筹办产生一个模子,终末通过damaver和dammin进行refine后不错通过RMS比较来取舍最优的值。

针对性建议(TROUBLESHOOTING)
1. 起初要明照实验目的,小角散射不像晶体衍射能解释到原子线索上,不同的目的需要用到的软件亦然不一样的,如果仅仅为了充数据,那么我照旧建议众人把更多的心念念放在长晶体上,不要以为小角散射是个偷懒耍滑的捷径。大部分情况下,小分子(小于80 kD)且单体卵白不妥贴作念小角散射,前边也提到了卵白越大越好,自然也不可是aggregate。如果是有规定的多聚体,那么不错用WAXS。
2. 其次,小角散射一般是援手型实验,比较妥贴与晶体结构或者NMR联用,如果仅仅单纯SAXS数据因为其分辨率很低的因素,无法得到具体的斥逐,但有一丝需要强调的是,它是检测卵白在溶液中的构象的很方便的技巧。因为同是溶液样品,NMR只可用在很小的样品,而SAXS在这一丝莫得什么限制。
3. 如果只须细目卵白的时势,不错只去前边的数据,不需要取那么多数据。
5.3 负染简介(INTRODUCTION)
负染就是用重金属盐(如磷钨酸、醋酸双氧铀)对铺展在载网上的样品进行染色;吸去染料,样品干燥后,样品凹下处铺了一薄层重金属盐,而凸的出方位则莫得染料千里积,从而出现负染着力。不错傲气生物大分子、细菌、病毒、分离的细胞器以及卵白质晶体等样品的时势、结构、大小以及名义结构的特征。
材料(MATERIALS)
试剂(REAGENTS)
2%或者3%醋酸铀
器械(EQUIPMENT)Gaten plasma systern、铜网、缜密镊子、格式化的U盘、Tecnai G2120kv电镜

实验格式(PROCEDURE)
一、 Tecnai G2120kv电镜基本操作格式
1. 准备格式
向冷阱中加液氮,如右图所示:电镜在在使用之前需要提前冷却,冷阱冷却镜桶概略需要1小时以上。
(1)插足电镜禁止系统(操作家需要插足我方的User账户),搜检电脑屏幕右下角托盘中如右图图标是否为绿色(![]() ),按纪律启动,按纪律启动TUI(Tecnai User Interface)和TIA(TEM Image and Analysis)系统。
),按纪律启动,按纪律启动TUI(Tecnai User Interface)和TIA(TEM Image and Analysis)系统。
(2)升高压,点High Tesion,将高压升至120 kv。
(3)开灯丝,点Filament(注:当万古期离开时,需关闭灯丝)。
2. 准备样品
旧例常温样品准备
(1) 制备带有样品的铜网。
用Gatan plasma system等离子清洗机处理铜网,氢气氧气处理10秒。
将自锁镊子夹住铜网,正面朝上,加5 μL样品,静置1 min吸附。用滤纸边际吸去满盈样品,加5 μL醋酸铀,静置1 min染色。用滤纸边际吸去满盈染液,灯下烤干15 min以上。
注:样品多且对温度不解锐时,可在封口膜上多个样品同期操作。样品可保存一周。
(2) 按下图将样品铜网固定在样品杆上。

(3) 取出下图红色箭头处的用具。

(4) 使用该用具将样品杆末端的弹簧夹掀翻,用镊子把样品铜网放入样品。
注:铜网插入电镜前,必须完全干燥。
3. 插入样品杆
常温旧例样品杆
(1)确立抽真空时期:Vacuum>setting>pumping time>120 s
(2)搜检镜筒阀是否关闭,黄色(Col.Valves Closed)走漏关闭。Setup>Col.Valves Closed

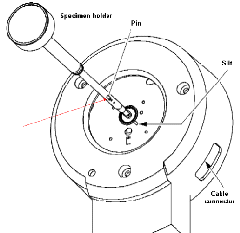
(3)将样品末端的轻细针尖(下图中红色箭头所示位置)瞄准样品台上的细缝(五点钟位置),插入样品杆。预抽轮回将会自动开始,请恭候直至样品台上红色劝诱灯灭火。下图箭头所示红灯灭火后,将样品杆逆时针旋转至少十二点钟位置,然后注意逐渐将样品放入。
(4)搜检确立页中镜筒真空读数,即Column值是否为20以下,若在20以下,即可掀开镜筒阀,点击“Col.Valves Closed”按钮,此时V4和V7阀会被掀开,即可开始不雅察样品。
4. 电镜基础蜕变
(1)Eucentric Focus
作念alignment前,必须按下Eucentric Focus,如下图所示:用Intensity改变光斑大小的时候,最好顺时照明(即顺时扩大光斑)


(2)蜕变Z-high,使样品位于Eucentric height
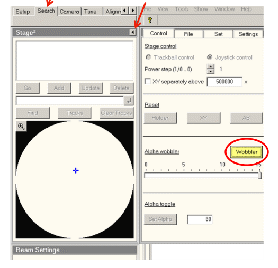
寻找样品中一特定物体看成参照物,激活Alpha Wobbler,样品台正负15°舞动,蜕变Z轴按钮使荧光屏上的主见物近似不动,如下图所示:

(3)Gun tilt
激活Direct alignment中的gun tilt 功能后,用Multifunction X/Y旋钮将荧光屏上的电流值(screen current)调到最大,肉眼不雅察是调至光斑最亮时。
(4)C2聚光镜光栏对中及象散矫正
A. 聚光镜光栏居中,插入聚光镜光栏(一般生物样品用3号光栏),
Intensity逆时针聚拢电子束,Beam Shift移光到中心,顺时散开电子束,若光斑与荧光屏不是齐心相切,则蜕变C2光栏上的X/Y(如下图所示)旋钮使光斑齐心相切。

重复以上格式,保证光束于最小和最大状态下齐位于荧光屏中心。
B. C2聚光镜象散矫正
若光斑呈卵形,则说明C2聚光镜有象散,需要矫正取舍Stigmator功能(如下图),点Condenser。
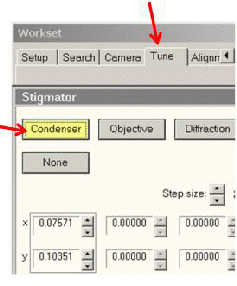
如下图,使用面板中的多功能按钮,蜕变X和Y方进取的象散修订线圈的强度,使光束变圆况兼能够齐心散开。

C. 点击蜕变页中的None按钮,杀青象散蜕变。
(5)Direct alignment
如下图所示,转到用户界面中的蜕变页,取舍平直蜕变式样。
A. Beam tilt pivot point
按序取舍下图中红框内的每一项,使用禁止面板上的多功能蜕变旋钮,使荧光屏中的两束光重合,且颤动最小。
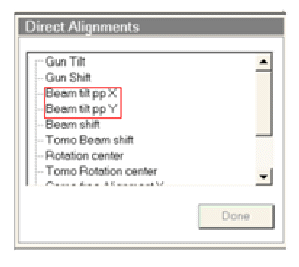
B. Beam shift
取舍Beam shift式样,使用多功能蜕变旋钮,将光束迁移至荧光屏中央。
(6)物镜光栏居中及物镜象散矫正
A. 物镜光栏居中
在diffraction模式下插入物镜光栏(一般生物样品用三号光栏),蜕变物镜光栏上的X/Y旋钮将物镜光栏居中。

B. 物镜象散矫正
在有碳膜区域,稍欠焦状态下,CCD不雅察,如上图,激活Live FFT,Stigma→objective→MF X/Y将傅立叶环调成圆形。
(7)Gain reference(选作念,作念ET必须要作念的一步)
A. 去除暗电流:
(a)找一个空缺区域,光散开。
(b)关掉column。
(c)CCD/TV Camera→Bias gain reference→All Bias。
B. Gain reference
(a)开column。
(b)在空缺区域,光散开至整个这个词荧屏。
(c)点击All gain。
C. 检测gain reference的着力
(a)Acquire一张图。
(b)点击TIA软件右边的Auto-Correlation(作念的好的状态是唯有中间有一个亮点)。
注:作念冷冻电镜时,上述的电镜基础蜕变格式需要在Exposure模式下作念
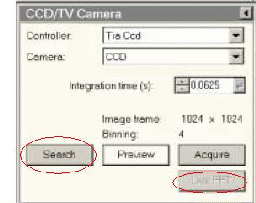
5. 样品不雅察
low dose
(1)采纳Search、Focus和Exposure所需要的放大倍数及Spot size及所需要的光斑大小。
(2)Search模式与Exposure模式位置瞄准,找一个彰着的样品参照物,在Exposure模式下用样品扭杆将参照物移到视眼中央,在切换到Search模式下,点击low dose→option→search shift,蜕变MF X/Y,将参照物移到视眼中央。
(3)在Search模式下寻找样品,Focus模式下蜕变焦距,Exposure模式下拍照。
5.4 冷冻电镜样品制备简介(INTRODUCTION)
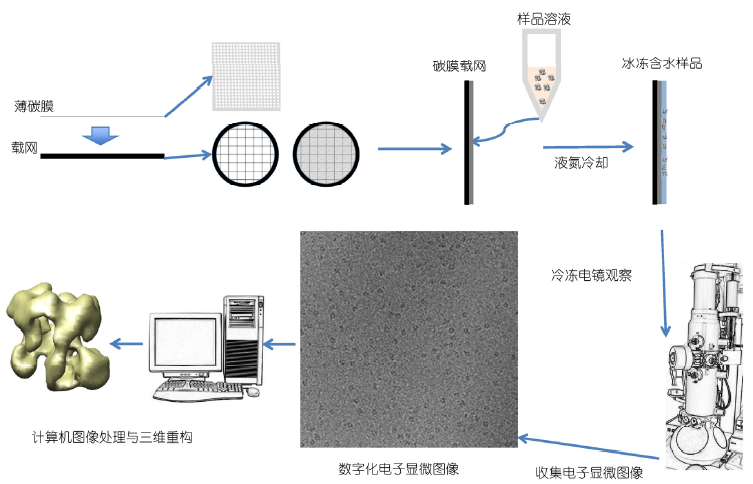
在低温下使用透射电子显微镜不雅察样品的显微工夫,就叫作念冷冻电子显微镜工夫,简称冷冻电镜(cryo-electron microscopy,cryo-EM)。
冷冻电子显微学认识生物大分子及细胞结构的中枢是透射电子显微镜成像,其基本过程包括样品制备、透射电子显微镜成像、图像处理及结构认识等几个基本格式(图1)。在透射电子显微镜成像中,电子枪产生的电子在高压电场中被加快至亚光速并在高真空的显微镜里面畅通。根据高速畅通的电子在磁场中发生偏转的旨趣,透射电子显微镜中的一系列电磁透镜对电子进行蕴蓄,并对穿透样品过程中与样品发生相互作用的电子进行聚焦成像以及放大,终末在记录介质上形成样品放大几千倍至几十万倍的图像,专揽筹办机对这些放大的图像进行处理分析即可取得样品的缜密结构。
样品需求量少:一个冷冻样品只需要3~5 μL 0.1~1 μmol 的卵白质溶液;更接近生理状态:冷冻电子显微学通过将样品快速冷却至玻璃态冰达到固定生物含水样品的目的,其不雅察的结构信息基本上反应样品冷却前的瞬时状态;适用研究对象平常:从细胞、细胞器到分子量在200 kD以上(最近的一些责任报说念了分子量在200 kD以下的卵白质分子的冷冻电镜结构)的大分子复合体。
材料(MATERIALS)
器械(EQUIPMENT)
Vitrobot
实验格式(PROCEDURE)
Vitrobot制样基本操作
1. 加水:用针筒从底下软管注入纯水,梗概20~30 mL。
2. 装滤纸:掀开机器,装上滤纸,点击Resetblotpaper。Blot缺陷。
3. 确立参数
(1)Console下确立:温度(一般确立为22 °C),湿度(设为100%)
(2)Options下确立:
A. Miscellaneous:
选上“Use Footpedal”、“ Humidifier Off during Process”、“ Skip Grid Transfer”
B. Process paprameter下确立以下参数:
Blot time(S):滤纸吸附铜网液体时期
Blot force:滤纸夹铜网的力度
Wait time(S):吸附前的恭候时期
Blot total:滤纸吸附次数
Drain time(S):Blot后的恭候时期
Skip application:跳过加样
4. Ethane Container准备责任
从中间的孔加液氮,充满整个这个词Ethane Container,让其冷却。等中间孔中液氮蒸发完后再向孔中加少许液氮再次冷却,同期将孔外面液氮加满。等孔中的液氮完全蒸发后开始通乙烷,乙烷加八分满。待乙烷固液共存状态时移走导热杆。
注:等孔中液氮完全蒸发后开始通乙烷。液氮干净崭新,液氮罐干燥。
5. 制样
(1)装镊子
镊子夹好铜网后(铜网需预先作念glow discharge),装在vitrobot上,让铜网正面朝右,镊子有字一面朝向操作家。踩一下脚踏板,将镊子升上去。
注:铜网要夹紧
(2)将Ethane Container放在操作台上,踩一下脚踏板,将Ethane Container升上去。
(3)掀开Humidity,将湿度升到100%后关掉。
(4)踩一下脚踏板,镊子掉下一丝,加样品。
(5)踩一下脚踏板,滤纸吸附满盈样品→镊子快速掉进乙烷中→Ethane Container降下来
(6)补充液氮,取下镊子。提神不可碰撞铜网,也不可将铜网离开乙烷。
(7)将Ethane Container迁移至桌面,拖沓镊子上的固定圈,将铜网赶紧迁移到液氮中然后迁移至样品盒内。
6. 收尾责任
取出滤纸,镊子用电吹风吹干,将Container中的液氮和乙烷倒掉后放入透风橱风干,退出纪律关机,关闭Vitrobot的电源。抽出剩余的纯水。将整个物品归位,登记使用记录。
5.5 卵白结晶实验
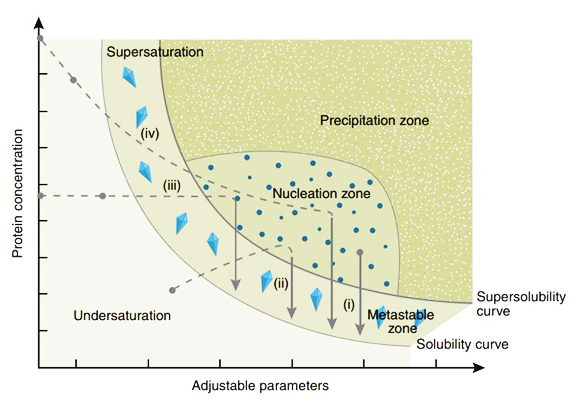
5.5.1 结晶筛选简介(INSTRUCTION)
卵白结晶是一个有序化过程:即卵白质由在溶液中就怕状态蜕变成有规定排列的状态。当卵白质溶液达到过饱和状态时,能够形成一定大小的晶核,溶液等分子失去开脱畅通的能量,赓续结合到形成的晶核上而长成妥贴 X 射线衍射的晶体。结晶过程分为两步:起初形成晶核,尔后形成晶体。其中形成晶核是一个重要的格式。以卵白结晶的相变过程简要先容结晶的一般方法以及触及到的重要因素。有4种主要的卵白结晶方法:(Ⅰ)批量结晶法(Microbatch);(Ⅱ)气相扩散法(Vapor Diffusion);(Ⅲ)透析法(Dialysis);(Ⅳ)开脱界面扩散法(Free Interface Diffusion)。尤以气相扩散法最为常用,又细分为悬滴法(Hanging Drop)和坐滴法(图Sitting Drop)。卵白浓度、千里淀剂浓度、添加剂浓度、pH、温度等齐是影响卵白结晶的重要因素。这里以气相扩散法来说明卵白结晶的相变过程(图Phase Diagram),假设浓缩的卵白溶液与母液以一定比例搀杂后形成的液滴刚开始是澄澈的,也就是说卵白质分子尚处于非饱和状态,由于搀杂的液滴与下槽的母液齐处于闭塞环境中,况兼母液的浓度要高于液滴的浓度,因此跟着时期的延迟,借助水蒸气的扩散,液滴的水分会冉冉减少,意味着其中的卵白质浓度与千里淀剂浓度齐会冉冉升高,直到条件变化至Nucleation zone中,晶核形成,随后溶液中的卵白分子赓续自愿地结合到形成的晶核上从而长成妥贴X射线衍射的晶体,即相变至Metastable zone Nucleation zone至Metastable zone 的过程中不错看到液滴中的卵白浓度是直线下跌的。

材料(MATERIALS)
试剂(REAGENTS)
目的卵白、结晶板、凡士林、硅化盖玻片等耗材
器械(EQUIPMENT)
恒温培养箱、体视显微镜
实验格式(PROCEDURE)
1. 评估卵白样品:
浓度鸿沟:5~25 mg/mL;MBP 交融卵白尽量浓缩至 30 mg/mL,以致50 mg/mL以上。一般水溶性好的卵白,运行浓度要求高一些。分子量小的卵白,浓度要求高一些。分子量大的的卵白,浓度要求低一些。在纯化到目的卵白之后,点晶体之前,需要对目的卵白作念尽量多的状态评估,以擢升实验着力。广泛卵白状态评估常见问题。
(1)卵白纯度。纯度是结晶性能最病笃的前提条件。纯卵白意味着翻译后修饰不存在异质性,也意味着杂质占总卵白质的含量较低,如1%。可通过运行一块过载的凝胶电泳来检测卵白纯度。如果要结晶卵白-卵白复合物,在建立结晶前需要进一步纯化,使形成复合物的卵白从未形成复合物的卵白等分离。
(2)卵白折叠。可检测卵白活性,也可检测卵白的圆二色谱(CD)来反应卵白是否正确折叠。
(3)崭新制备卵白。卵白会跟着时期降解使搀杂物变得不均匀。最好在卵白纯化完成确本日进行结晶实验。
(4)单一的卵白团聚状态。如仅存在单体或二聚体的猖狂一种。可将分子筛纯化方法看成卵白纯化的终末格式。可使用动态光散射器细目卵白的团聚状态。
(5)卵白浓度。
(6)卵白在室温下是否褂讪。是否需要添加一些东西(如盐)。卵白降解是否赶紧。
(7)雷同的卵白是否结晶过?搜检PDB并检察头部记录以取得结晶化细节。
2. 取舍稳妥的晶体筛选试剂盒。
市售多种卵白结晶筛选试剂盒,大多是基于就怕法或者不完全因素法(Sparse matrix screen)想象的。最早由McPherson报说念,网罗了最常见的卵白结晶条件,把这些因素作当场组合而成。最经典的就是Hampton Research 的Crystal Screen Kit。其后新开发的试剂盒,参考了更多卵白样本。还有一些有一定针对性的试剂盒,比如针对卵白复合物的试剂盒,Protein Complex Screen, 由NIAID Peter Sun组想象。Hampton Research公司的Natrix Screen针对核酸卵白复合物的结晶。TJ-Lab有常见的10多种结晶试剂盒,不错根据需要和样品脾气取舍。
3. 卵白样品需要取舍稳妥的缓冲液。
需要对卵白缓冲液的喜好有一定的了解。比如,缓冲液pH辩认卵白等电点1~2个单元,尽量减少盐或者其他组分(比如甘油)。遁入磷酸缓冲液,因为磷酸根容易与钙/镁离子互作,形成盐晶。根据需如果不是需要加复原剂如DTT等。
4. 悬滴法结晶实验的建立,展望浪掷时期:2 hr/kit
(1)挑选需要用到的 Crystallization Kits(见附录),按照 Kits条件的纪律,在结晶板(一般 24孔)的盖子上作念好编号,每完成一块结晶板的编号,切记将结晶板的盖子与底座作念上独一标记,以防在后续格式中不同结晶板的盖子与底座欺压。
(2)完成对结晶板的编号与标记后,逐一双应地将Kits中各条件溶液加入到各孔中,即加入下槽液,下槽液的体积一般为250~300 μL(如果是优化条件,为方便筹办,体积为500 μL。
(3)根据目的卵白的个数或浓度,预先想象好在一块盖玻片上点几个悬滴,细目数量(如4~6个),进一步细目悬滴间的位置,在结晶板的盖子上最好画一个盖玻片的示意图,将悬滴间的位置关系在示意图上标记清晰,钟情盖玻片正反面视角不雅察导致的悬滴间位置关系的各别,同期在结晶板的盖子上标记清晰姓名、实验日历、卵白称号、卵白浓度等关系信息。
(4)按照设定的纪律,将目的卵白点在盖玻片上,吸取对应的下槽液与之搀杂(目的卵白的滴加量根据浓缩后的体积而定,确保目的卵白的量是足以点完整个条件的,一般目的卵白的滴加量为0.2 μL;下槽液的滴加量取决于其与目的卵白的比例,一般为1:1)。
5. 悬滴搀杂完成后,将盖玻片盖在对应的孔上,压须臾用劲适中,确躲藏封(如果结晶板莫得自带封胶,那么需要在加入下槽液之前,在每个孔边际东说念主工均匀地涂上凡士林等封胶);
重要格式:每点完一块板就当场将其移入18 °C恒温箱中,直至点完整个条件。
6. 不同卵白结晶速率快慢不一,因此不雅察晶体形成情况的时期也莫得法律解释,一般是在第二天进行第一次不雅察,将结晶板从恒温箱中取出,在显微镜下逐孔不雅察,提神不雅察时尽量赶紧,幸免明朗、温度等外界条件的变化对晶体形成影响。
7. 根据教会,对每孔中结晶情况进行判断,如遇疑似目的卵白的晶体,将对应的悬滴标记出来,留待进一步细目或冻存(大多数情况下,初步筛选一无所获是很正常的,少数交运情况下,会不雅察到晶体或一些疑似晶体的物资,可能存在各式形态,或太密集,或太小,或极不规定等等,此时就需要对结晶条件进行优化)。
8. 不雅察杀青后,将出现疑似晶体的孔的编号记录下来,当场将结晶板放回恒温箱中,对照Kits的说明书及母液管壁上的详细,将记录下来的编号对应的条件挑选出来,并另记于实验本。
9. 根据目的卵白初筛时出晶的概略时期,对优化的条件进行显微镜不雅察,如果能够不雅察到单个晶体,应该尽快将晶体冻存起来,留待衍射。
影响出晶的试剂身分参考
1. 团聚物分子量大小:
不同分子量的团聚物比如PEG,和水作用方式不同,千里淀卵白才略也不同。一般来说,分子量大的PEG,千里淀着力更强,更容易产生晶核。相背,分子量小的PEG,更谢却易让卵白千里淀和结晶。因此有的卵白在较低浓度高分子量PEG(比如PEG8000)下能长晶体,但是不可在高浓度低分子量PEG条件下出晶体。另外,低分子量PEG,包括EG,PEG400等,齐是很好的防冻剂。在高分子量PEG条件下长的晶体,不错添加20%摆布的EG或者PEG400来防冻。根据PEGs的相似性和不同性质,优化晶体的时候,不错尝试不同分子量的PEG,以取得高质地单晶。
2. 盐的种类和取舍:
盐的种类好多,对卵白质结晶的影响也各有不同。总的来说,基本合适Hofmeister定律。电解质溶液的名义张力推崇出“特殊离子效应”,名义张力会跟着盐溶液浓度的增多而增大,而在浓度增量疏导期不同的电解质溶液的名义能增量不疏导,这个表象被认为是Franz Hofmeiste效应。从普遍实验看,Hofmeister序列离子对溶液的影响在盐浓度高的溶液中较彰着,且阴离子的影响要大于阳离子的影响。模拟研究标明,溶剂化能在离子和周围水分子之间的变化是Hofmeiste效应形成机制的基础。Hofmeister序列如下:SCN-<I-<ClO4-<NO3-<Br-<ClO3-<Cl-<BrO3-<F-<SO42-<K+<Na+<<Li+~Ca2+。序列中头几种离子增多溶剂名义张力,责怪非极性盐析分子的溶解度(盐析),加强了疏水作用。而终末几种离子增多非极性盐溶分子的溶解度(盐溶),增多水的有序性,责怪了疏水作用。盐析效应广泛用于卵白质纯化,专揽硫酸铵千里淀。然则,这些盐也平直与卵白质相互作用(卵白质带电且具有强偶极矩),以致不错特异结合(例如磷酸盐和硫酸盐与RNaseA结合)。具有历害“盐溶”效应的离子,如i-和SCN-是强变性剂,因为它们在肽基团中盐化,因此与未折叠的卵白质相互作用比与自然卵白质相互作用更强,它们将去折叠反应的化学均衡迁移到未折叠卵白上。在一个含有多种类型离子的水溶液中,卵白变性愈加复杂。

针对性建议(TROUBLESHOOTING)
实验前确保卵白样品比较均一。高速离心去除卵白千里淀,擢升卵白均一性。
5.5.2 结晶条件优化简介(INSTRUCTION)
专揽晶体学方法获取卵白结构常常需要付出极大的苦恼,因为很厚情况下,取得高质地的晶体是很穷困的,大多数时候莫得晶体或者唯有低质地的晶体,例如出现孪晶、晶体太小、晶体
衍射等等。以下是一些常见对于晶体优化等关系内容。
如果只可得到微晶,那么不错通过改变结晶条件:千里淀剂浓度、pH(有时,0.1 pH单元的改变足以影响出晶)、卵白浓度(擢升液滴中卵白质的比例不错擢升卵白终浓度)、温度(如果需要4度结晶,可在结晶前预冷整个的溶液并冰上操作)、方法(更大的液滴不错形成更大的晶体,因为液滴中含有更多的卵白质,均衡的速率更慢。也不错尝试坐滴或三明治滴)、卵白自身。
一、如果无法擢升,不错尝试改变卵白
1. 配体-卵白复合物。如果你的卵白质结合配体可制备配体-卵白复合物,因为配体的结合可能会结合两个子结构域而责怪纯真性,将改变卵白质的名义脾气,可能会导致卵白构象改变。
2. 均质性。非均质的第三四级结构终止结晶。 你的卵白质解析成一个褂讪的卵白水解片断(或者是“自愿的”,或者在一个附加的卵白酶的匡助下)吗?你的卵白质与吞并眷属其他卵白质的同源性是否责怪到n-和c-末端?
3. 结构域。你的卵白质有结构域结构吗?可通过搜检Pfam数据库,搜检ProDom数据库,Psiblast搜索获悉。
4. 低复杂性区域。有时,点突变可梗阻/启动卵白质结晶。研究不同的物种是取得不影响功能的点突变聚首的最苟简方法。
5. 脱糖基作用。对于糖基化修饰的卵白质,松软和不均匀的碳水化合物可能会侵犯结晶。可尝试酶促脱糖。
6. 添加剂及洗涤剂。最受接待的添加剂有:甘油,(广泛用量1%~25%的甘油),不错梗阻成核,并可能给你更少,更大的晶体,并具有双重看成冷冻保护剂的上风。酒精或二氧六环,这些物资会毒化晶体并使晶体住手助长幸免成核过多。二价阳离子,如镁。洗涤剂,如β-辛基葡萄糖苷。Hampton有三个添加剂筛选和三个洗涤剂筛选试剂盒。找到合适的添加剂可能与找到卵白质单一团聚态的条件关系。尝试使用不同的添加剂得到单一团聚态卵白。
二、晶体衍射关系影响因素:
1. 衍射:衍射取决于晶体大小。因为散射与晶体中的单元胞数成正比。单元晶胞的数量与晶体的体积成正比,因此将立方晶体的整个尺寸加倍,衍射就会达到8倍。相背,晶体中单元晶胞的数量取决于单元晶胞的大小,而单元晶胞的大小又取决于卵白质的大小。
2. 次第:散射取决于每个单元的疏导程度。 吞并性越强,散射越强。盐比卵白质衍射更好,因为它更有序。
3. 对称性:对于相通大小的晶体,盐的衍射着力比卵白质的好,因为单元晶胞要小得多。(盐晶衍射的光斑相距较远,在一个小的回荡角鸿沟内,光斑可能会消亡。在高分辨率下会有一些历害的雀斑,不会看到低分辨率的雀斑。)
4. 晶体的衍射质地不错随以下任何组合而变化:
衍射强度
衍射质地
无衍射
多嵌入晶体Multiple mosaic crystal
弱衍射10埃
嵌入晶体
衍射3.5-6埃
多晶体
衍射>2.8埃
单晶体
材料(MATERIALS)
试剂(REAGENTS):目的卵白、结晶板、凡士林、硅化盖玻片等耗材
器械(EQUIPMENT):恒温培养箱、体视显微镜
实验格式(PROCEDURE)
1. 细目晶体助长条件。本实验室我方配制的晶体母液,因短缺某些试剂,该试剂可能由其他试剂替代。建议在细目晶体助长条件时以母液管壁上标注的说明为准。
2. 拟定优化决议。一般情况下将千里淀剂浓度拉梯度(自然也有其他方法,下文中会有所触及),具体的作念法是先设定梯度的两头值(即千里淀剂的最小浓度和最大浓度),当场配制好相应的两份母液,然后吸取两份母液按不同比例搀杂以完成梯度确立(例如,出晶的条件中千里淀剂是2.0 M的硫酸铵,那么不错将梯度确立在 1.5 M 至 2.5 M之间,配制两份结晶母液其含有千里淀剂浓度分辨为Solution A(1.5 M)和Solution B(2.5 M),提神这两份结晶母液中只改变了千里淀的浓度而其他身分的浓度和原始结晶条件一致。如果准备点6个孔的话,不错按如下比例分辨吸取两份母液搀杂于相应孔中,如下表:
1
2
3
4
5
6
Solution A (μL)
500
400
300
200
100
0
Solution B (μL)
0
100
200
300
400
500
3. 自然也不错按照每50 μL为基础变量进行递减/递加,这样会产生11个条件。
4. 如果要以pH为优化变量,或者确立条件组合,方法同上述雷同。
5. 根据目的卵白初筛时出晶的概略时期,对优化的条件进行显微镜不雅察,如果能够不雅察到单个晶体,应该尽快将晶体冻存起来,留待衍射。
针对性建议(TROUBLESHOOTING)
1. 如何将多块嵌入晶体制成单块晶体?
一些多晶体不错使用玻璃纤维轻轻分开。
拍摄崭新的晶体。晶体在助长后的几天内就会变质。
嵌入晶体需要仔细的数据网罗。如果嵌入性不会导致雀斑相互重复,则不错进行数据网罗。
2. 如何使弱衍射晶体进一步衍射?
提神辐照挫伤。有些冻存的晶体在X射线映照下会衰减。晶体逝世表目前第一幅衍射图像上有微弱的衍射,第二幅图像上的衍射更少。
拍摄崭新的晶体。轻轻地处理晶体,使用大环来冷冻。
脱水。将晶体置于较高的千里淀剂条件下使细胞收缩。这不错在分辨率上产生惊东说念主的擢升。
退火。把晶体冷冻在低温流中(不要射击),把它们放回室温,把它们放回结晶溶液中几分钟,然后重新冷冻。
关系文献及竹帛:J. M. Harp, D. E. Timm and G. J. Bunick (1998). Macromolecular Crystal Annealing: Overcoming Increased Mosaicity Associated with Cryocrystallography. Acta Cryst. D54, 622 - 628. 以及J. I. Yeh and W. G. J. Hol (1998). A flash-annealing technique to improve diffraction limits and lower mosaicity in crystals of glycerol kinase. Acta Cryst. (1998). D54, 479 – 480.
5.5.3 晶体冻存简介(INTRODUCTION)
当取得了目的卵白的晶体后,咱们如何让它能够隐忍得了X-Ray一定时期内的捏续映照,并取得较好的衍射数据呢?
因为晶体平直被显现在X-Ray的映照下,在极短的时期内,晶体里面的排列纪律就会受到蹂躏而无法取得足够的衍射数据,因此就需要一定技巧来保护晶体。研究发现当晶体处于超低温的环境中,不错延迟晶体显现于X-Ray的时期,看守里面分子的排列纪律。因此,现普遍遴荐低温冷却的方式来保护晶体以取得更多的衍射数据。然则,平直低温冷却晶体会致使晶体里面产生冰晶,以至于蹂躏了卵白晶体里面的有序结构,因此保护晶体的各式防冻剂被科学家们冉冉通过测试而挖掘出来,成为晶体学实验不可或缺的病笃一环。防冻剂的取舍是需要实验东说念主员根据教会和履行情况屡次摸索,也不错凭教会开脱组合一些防冻身分已达到实验目的。
常用晶体防冻液
Cryoprotectant
Concentration
Glycerol
>25%
Ethylene glycol
>25%
PEG-400
>25%
2R,3R-(-)-Butane-2,3-diol
>25%
Paraffin
>25%
2-propanol
>25%
2-Methyl-2,4-pentandiol (MPD)
>25%
Glucose
>25%
Xylose
>25%
Sucrose
>25%
Li2SO4
>2 M
材料(MATERIALS)
试剂(REAGENTS):防冻剂、结晶母液、Puck、Cryopin、枪头 等耗材
器械(EQUIPMENT):液氮(罐)、绝热盒、显微镜、钳子、移液枪
实验格式(PROCEDURE)
1. 防冻剂的取舍相配重要。自然上表多种化合物齐有防冻着力,但是用法有些不同。起初尽量遴荐相似原则,也就是说及第与结晶条件疏导或者接近的组分。比如如果晶体是在含有PEG条件长的,通过增多PEG的浓度或者添加高浓度小分子量的PEG,达到防冻着力。如果晶体是在高盐条件长的,不错首选具有防冻作用盐,比如锂盐,其次是小分子糖类葡萄糖、木糖、蔗糖等。甘油具有责怪电导的作用,常常对在高盐条件下的晶体不利。其次,通过搀杂多种组分防冻剂,最大限制减少对晶体形成挫伤。比如10%甘油,10% PEG,10%蔗糖等。防冻剂的取舍还要商量的防冻剂在结晶条件下的溶解度。比如硫酸锂溶解度较低,很难达到防冻着力。
2. 配制防冻液时,需要保捏原条件千里淀剂浓度疏导或者稳妥增多。不可苟简在原条件里加防冻剂,这样会形成千里淀剂浓度责怪。防冻液的身分是整个身分的最终浓度,配制时需要商量体积的改变,以最终体积为准。
3. 配制好防冻液,用移液枪稍稍吸取一些防冻液于枪头顶部,置于盛有液氮的绝热盒中数秒,移出液面,不雅察防冻液是否结冰,如结冰(在液氮中变白),需调试防冻液身分或比例,直至防冻液不结冰,在 EP管上标记清晰防冻液身分和实验日历。
4. 准备好具有不同大小fibre loop(0.2 mm, 0.3 mm, 0.4 mm等)的Cryopin,在莫得揭开盖玻片之前,在显微镜下参照晶体大小比较并取舍出妥贴的loop。
5. 将Puck掀开(提神Puck的序列号),用钳子将其放入盛有液氮的绝热盒中(保证液氮 的量是足够的,整个这个词实验过程中看守绝热盒中液氮的液面跨越Puck 1~2 cm),使其充分冷却。
6. 准备好后,揭开相应的盖玻片,反过来放在结晶板的盖子上,置于显微镜下。
7. 用移液枪吸取少量防冻液(1~2 μL)于悬滴上(时代提神此时晶体的状态,是否熔化或者千里淀),再吸取少量防冻液于盖玻片空缺处(留用于涮loop)。
8. 用合适的Cryopin注意并赶紧地挑取晶体,在空缺处的防冻液中涮一下,使得晶体周边比较干净(提神不雅察晶体的状态)。
9. 晶体状态很好的话,赶紧将Cryopin放入绝热盒中Puck的相应位置(提神 Puck中孔的编号和善序),记录该晶体的各式关系信息(卵白浓度、结晶条件等),Puck序列号以及Puck中孔的编号,切记loop一朝插足液氮液面以下,务必保捏其永辽远于液面以下。
10. 按上述操作装满一个Puck后,将Puck的盖子用钳子放入液氮中,使其充分冷却,然后将Puck盖好(提神卡槽);。
11. 将Puck移入Puck架上,注意放入液氮罐中,整个这个词过程永久正置Puck,勿将其倒过来以致loop显现于空气中;
12. 绝热盒中满盈的液氮回收到液氮罐中,液氮罐置于实验室阴冷处。
搜检Pin金属杆是否周折(不是挑晶体的尼龙环),有彰着周折的一定不要用。
针对性建议(TROUBLESHOOTING)
1. 晶体冻存的重要重要就是配制合适的防冻液和挑取晶体的操作,此格式一定要注意严慎,千万不要让好谢却易长出的晶体因为准备不充分和操作乖张而毁于一朝。
2. 为了更好的重复,对各项信息要详备记录,包括卵白的批次,纯化的格式条件,卵白的浓度、纯度、储存条件等。这一部单干作一定要仔细完成。Puck有空位置的一定作念好记录。否则后果很严重。
5.6 晶体衍射及数据网罗简介(INTRODUCTION)
卵白质三维晶体结构是通过对一系列晶体衍射数据分析处理的斥逐。看成结构生物学实验室,晶体数据的网罗是咱们实验室的一项病笃责任。
本文将主要证明两部分,第一部分先容如何灵验轨范的记录、整理晶体的关系信息及冻存晶体的操作。第二部分先容如何使用HKL2000软件初步处理网罗的晶体数据。
实验格式(PROCEDURE)
1. 准备责任
(1)课题恳求:插足上海光源网罗数据需提前课题恳求,填写关系用户信息、实验安全审核等信息方能取得使用阅历。每年1月至7月,每月有一次晶体衍射机时。
(2)东说念主员分拨:咱们实验室每月会叮嘱东说念主员去上海光源讲求晶体衍射实验,目前该任务主要由李越龙同学讲求。同期,如果同期有几位同学齐准备了冻存的晶体样品,和金老诚商量后,有样品的同学不错跟从李越龙全部去上海网罗数据。
(3)光源用户注册:根据上海光源用户使用规定,每个插足上海光源进行实验的东说念主员必须提前在上海光源管理系统网站恳求个东说念主账号,取得上海光源个东说念主ID号。恳求光源个东说念主账号的格式如下:
(4)登陆上海光源用户课题管理系统http://ssrf.sinap.ac.cn/proposals/default.aspx 进行用户注册在填写个东说念主基本贵寓、给与安全培训并通过考试测试后取得用户编码(附录有测试谜底)。个东说念主需记起我方的用户名和密码并文牍李越龙我方的ID号,方便其记录并安排住宿,否则将无法入住光源宾馆,也无法插足光源收数据。
(5)办理出行讲解:提前到生科院找潘主任加盖学院公章,以便佩戴液氮罐上火车。
2. 冻存、网罗晶体
3. 出行指南
(1)科大→合肥南站→上海虹桥火车站:108路(6:00~21:30/22:30):稻香村→合肥南站,出租车约20元。订购动车或高铁火车票,约200元,时长3小时。
(2)虹桥火车站→地铁2号线(05:30~22:45):地铁进口就在火车站内,乘坐标的为浦东外洋机场标的,约18站到张江高科站下车,时长约一小时,单程票价6元。
(3)地铁站5号出口→应用物理所(张衡路):地铁站出口跨过马路左边标的有公交站和小吃摊,张南专线/188路或其他的:张江地铁站→3站路到张衡路科苑路下车(离光源近)或2站下车到马路对面吃饭,票价1或2元。也可打车,约12元。复返的道路不错到科伦路作念公交,因为张衡路上唯有一回班车。
(4)到光源后,从门卫那儿根据我方的用户编号领取剂量计和用户卡。
(5)宾馆房费200元/天可刷卡,但押金必须交现款,房间12点前要退房。
(6)光源供餐时期:早餐供应时期:周一到周五7:30~9:00;周六到周日8:00~9:00。午餐:11:00~1:00,晚餐:5:00~7:00。提神供餐时期,以便取舍时期应时就餐。
重要格式:作念好准备责任:身份证、走动火车票、整钱和零钱、硬盘和数据线、手机和充电器、水杯食物等。不错办理上海市的交通卡,无须每次齐备零钱(市内交通,吃饭用度一律不给报销)。
4. 数据网罗
(1)开门:先按关闸,再按开门。
(2)放PUCK:将液氮池上的陀螺拿通达在特意的位置,掀开盖子(提神电线),旋紧PUCK,放进液氮池,PUCK的凹槽瞄准定位杆(有两根)。将盖子盖上概略在中间位置,不要盖上陀螺。记录好每个位置对应的PUCK。
(3)关门:按搜索1→按搜索2→东说念主走出来→按关门→按住开闸3秒→开闸灯亮不错走了。
(4)操作演示器:如果是接着别东说念主的机时使用,点击运行化(点击之后会变成另一个名字,再次点击即可)。鼠标点样品→点Mount→点Center(对焦)多旋转几个角度,确保所要网罗数据的旋转角度内晶体齐处于Focus上→点Collect→定名存储数据旅途的文献夹、样品编号、确立参数、网罗(0#为单张image用于测试,1#为多张image换样品后重心reset)。
A. Energy不要动,distance走漏detector与样品的距离,越近收的数据越多但也可能有过多杂音,因此根据测试分辨率的大小判断用些许距离。Angle走漏每拍一次样品旋转的角度,一般为0.5~1°,在shutterless detector比如18U/19U一般是晶体mosaicity 的一半。Expose 走漏每次拍照曝光的时期,可根据测试时点数判断,点数过多减少曝光时期,曝光时期太长样品更易损坏。如果光很强不错使用衰减。Image 走漏拍些许张,不错根据空间点群判断,但在样品未损坏的前提下不错尽可能多的拍,一般至少360。
B. 衍射图点分散会比较好,如果连成线一般走漏栾晶,不错取舍边沿的位置曝光通过Beam stop看光的强弱,正在网罗的数据如果想住手网罗不错通过pause和abort 住手。
重要格式:一般不要使用衰减,收至少360°,不错一次性把晶体打坏。
(5)记录每个晶体x-ray的参数(距离、能量、角度、定名、曝光存储旅途等)。
(6)换样:点下一个样品→Mount→同格式4)。
(7)终末一个样品网罗完成后点dismount→关闸→开门→取出PUCK。但不要关闭可视化软件。
重要格式:
际遇空loop死机后,点击两次reset→点击initiate两次。
样品网罗收场后不要关闭软件,如果关闭,点击terminal窗口→↑键找回BlueIce敕令→Enter→点击Active(Collect页面的底下)。
(8)Copy 数据至自带的U盘。
重要格式:
线站频繁会掉光,听到播送掉光后,到上游的禁止箱→旋转钥匙到允许→关闸→卑劣关闸→旋转钥匙到禁止,重新注入光后,允许→上游开闸→卑劣开闸。
附:
常见空间群对应的最少网罗角度。最优政策下,需要用HKL2000初步处理,根据Strategy 筹办出来的肇始网罗角度。总的网罗角度一般是下表最少角度的两倍。
空间群
最少网罗角度
P1
360
P2
180
P3
120
P4
90
P6
60
5.7 单晶衍射数据网罗重心简介(INTRODUCTION)
数据网罗这一步相配病笃。底下是一些需要提神的方位,确保对每一颗晶体,网罗到最高质地的数据。
1. 晶体聚焦:相配病笃,需要在0度,90度,180度和360度多角度旋转,细目是否在中间。有的时候晶体环太大,网罗过程中的抖动,会移位。网罗过程需要监控数据。望望衍射责怪,是不是由于晶体迁移了。这点相配病笃!
2. 能量:晶体线站一般有推选最优波长,比如在1埃摆布,12.3 keV,看成收native晶体衍射数据的默许波长。如果是有重原子的晶体,根据需要调治。比如先扫重原子,再细目不同MDA/SAD波长。
3. 光斑大小:光斑不是越大越好,也不是越小越好。一般和晶体差未几大的光斑最好,一般遴荐50~200微米光斑。光斑大于晶体,容易增多配景。光斑太小,莫得把整个这个词晶体专揽上,衍射莫得到极限。如果晶体太大,比如大于0.5毫米,光斑不错稍小。如果大晶体,且里面不均一,有可能存在晶体的乖张,大光斑网罗的衍射点笼统,不可用。这种情况不错用较小光斑,比如5~10微米。
4. 衍射时期和衰减attenuation:需要根据晶体衍射才略和抗辐照才略细目。一般来说,衍射时期越长,衍射越强。X射线能量越强,衍射越强。但是万古期曝光,会增多探伤器的配景和晶体衰减。由于晶体的decay是开脱基介导的,需要一定时期。因此教会上,用高剂量短时期,比低剂量万古期收到的数据质地更高。因此,起初需要用不是最好的晶体作念测试。晶体在网罗一整套数据后,不雅察衍射才略是否彰着责怪。再采纳特定类型晶体能承受的X-射线能量,比如100%或者50%能量。然后细目曝光时期,一般0.2 s~2 s鸿沟。目前17U线站最强,一般无须衰减的话,遴荐0.2 s至0.5 s。19U能量稍弱,遴荐0.2 s至1 s。
5. 数据需要网罗的角度:也需要根据晶体抗辐照才略和空间群细目。初步处理以后,细目晶体空间群。如果P1,至少收720度;P2至少360度;P3是240度。履行情况是,如果晶体能够承受,时期允许,尽量加倍收。以后处理的时候不错不遴荐背面的数据。但是万一数据不完整,后悔来不足了。
6. 每张图的角度:有研究发现fine-slicing有自制。论断是mosaicity的一半最优。因此如果时期允许,用较小角度,而不是整个齐用1度。19U建议默许0.5度,而17U新检测器相配快,建议用0.1-0.5度。
7. 数据初步处理:建议网罗现场处理数据,这景色不错细目所网罗的数据质地。万一发现问题,晶体还在,不错重收。况兼现场就把每套数据处理完的分辨率、完整性等数据整理记录,幸免时期长后弄错。空间群和收数据的政策关系。因此初步细目空间群后,不错开始解结构。结构解出来,以能修下去为准,且对背面优化网罗参数也有率领作用。
8. 数据记录备份:整个晶体和数据齐需要有详备记录,回实验室后实时作念备份。数据需要全部重新理优化,实时认识结构。根据数据质地和结构认识的情况,细目前一步优化晶体的情况。
9. 些许晶体,收些许次数据才够?一颗晶体足够认识结构。原则上,一种晶体(或在吞并条件长的)每次未几于8个。预先需要优化,得到最好的晶体。长得单晶,三维最大,莫得彰着缺陷。只带最好的晶体去收数据。每种晶体在每次收数据后齐要得出一个论断,比如这个条件是否不错,是否需要立异。咱们不建议吞并个晶体重复网罗好屡次数据(比如三次)。
10. 数据处理cutoff:你的数据切到哪?需要概括商量,比较主不雅。保守的轨范是I/σ=2。激进的轨范不错是I/σ=1。同期需要参考其他轨范,比如completenesss 85%以上,冗余度redundency>5(至少>3),CC(1/2)>66, Rmerge 和Rmeas,不是很病笃,不错参考Rpim。
11. 空间群的决定:根据数据建模,systemic absence初步细目,能够解出结构况兼把结构修好是金轨范。
5.8 XDS预处理衍射数据简介(INTRODUCTION)
XDS是一个用来处理X-ray晶体衍射图的软件包。包括XDS,它能处理一套数据;XSCALE,用于scaling多套数据;XDSCONV,用于把XDS输出的数据转化成其他格式。同期还有cellparm, 2cbf and merge2cbf. XDS-viewer,后者是一个独处的软件,用于傲气衍射图的。更多信息,请参考xdswiki:-konstanz.de/xdswiki/index.php/Main_Page
目前该软件主要照旧在linux/unix系统下以敕令的时势运行。
实验格式(PROCEDURE)
一、使用前安装(以MAC OSX为例):
1. 把下载的安装包解压,把XDS-OSX_64文献夹移到Applications中。
2. 掀开terminal,输入:echo $SHELL,检察我方电脑的shell,一般齐是bash shell。
然后接续输入:open –a TextEdit ~/.bash_profile,这时会弹出新的窗口,上头傲气的齐是荫藏敕令。在这个新窗口中另起一瞥,输入:export PATH=full_path_name_to/XDS-OSX_64:$PATH
export KMP_STACKSIZE=8m
3. 在terminal中插足XDS-OSX_64文献夹,输入:pwd,会傲气该文献夹的旅途。将此旅途复制粘贴到第四步中的full_path_name_to/XDS-OSX_64,代替它。回车。
4. 到末端中输入:xds,看是否不错运行。
XDS使用一段时期会提醒落伍,这时不错到官网-heidelberg.mpg.de/html_doc/XDS.html 重新下载安装包,按照以上格式重新安装即可。
二、数据处理时:
1. 修改XDS.INP的参数:
!背面一瞥走漏软件跳畴昔,也就是伪善践的敕令。请使用稳妥的文本剪辑器,比如linux 下nedit或者Mac下TextEdit。
2. 在存独特据的文献夹里,新建一个xds的目次,然后插足改目次:mkdir xds/cd xds
3. 把以前的xds文献夹,包括整个输入文献INP文献拷贝过来:Cp *.INP xds/
4. 使用稳妥的文本剪辑器,比如linux下的nedit或者Mac下的TextEdit:Nedit XDS.INP / open –a TextEdit XDS.INP
5. 你将会看到如下内容。红色的方位是需要提神或者修改的方位,其他方位一般无须变。
6. DETECTOR=PILATUS这是18U/19U的shutterless的detector。它有好多块构成。和17U的不同。如果是在17U网罗的数据,请另外掀开一个针对17U的XDS.INP文献。
底下这些岂论在那儿网罗,齐是一样的。
!====================== JOB CONTROL PARAMETERS
!JOB= XYCORR INIT COLSPOT IDXREF DEFPIX XPLAN INTEGRATE CORRECT
!JOB=ALL
JOB= DEFPIX INTEGRATE CORRECT
这一部分是取舍任务。第一次选JOB=ALL。细目空间群后,取舍底下的JOB=DEFPIX INTEGRATE CORRECT
!====================== GEOMETRICAL PARAMETERS
!ORGX and ORGY are often close to the image center, i.e. ORGX=NX/2, ORGY=NY/2
ORGX=1224.0 ORGY=1253.5 !Detector origin (pixels). ORGX=NX/2; ORGY=NY/2
DETECTOR_DISTANCE= 400.0 !(mm)
ROTATION_AXIS= -1.0 0.0 0.0
! Optimal choice is 0.5*mosaicity (REFLECTING_RANGE_E.S.D.= mosaicity)
OSCILLATION_RANGE=1 !degrees (>0) 转角
X-RAY_WAVELENGTH=0.9785 !Angstroem 波长
INCIDENT_BEAM_DIRECTION=0.0 0.0 1.0
FRACTION_OF_POLARIZATION=0.99 !default=0.5 for unpolarized beam
POLARIZATION_PLANE_NORMAL= 0.0 1.0 0.0
!======================= CRYSTAL PARAMETERS ==============
!SPACE_GROUP_NUMBER=196 !0 for unknown crystals; cell constants are ignored.如果不知说念,就跳畴昔或者输入0,前边一次输出的不错看成下一次的输入。
! UNIT_CELL_CONSTANTS= 180.7 180.7 180.7 90 90.0 90.0
SPACE_GROUP_NUMBER= 168
UNIT_CELL_CONSTANTS= 123.81 123.81 120.15 90.000 90.000 120.000
FRIEDEL'S_LAW=TRUE ! Default is TRUE.
!REFERENCE_DATA_SET= CK.HKL !Name of a reference data set (optional)
!==================== SELECTION OF DATA IMAGES ==============
!Generic file name and format (optional) of data images
DATA_RANGE=1 180 !Numbers of first and last data image collected 使用的数据
BACKGROUND_RANGE=1 6 !Numbers of first and last data image for background
SPOT_RANGE=1 90 !First and last data image number for finding spots,用来运行选点的数据,一般是使用数据的一半。
!==================== DATA COLLECTION STRATEGY (XPLAN) =============
! !!! Warning !!!
! If you processed your data for a crystal with unknown cell constants and
! space group symmetry, XPLAN will report the results for space group P1.
!STARTING_ANGLE= 0.0 STARTING_FRAME=1
!used to define the angular origin about the rotation axis.
!Default: STARTING_ANGLE= 0 at STARTING_FRAME=first data image
!RESOLUTION_SHELLS=10 6 5 4 3 2 1.5 1.3 1.2
!STARTING_ANGLES_OF_SPINDLE_ROTATION= 0 180 10
!TOTAL_SPINDLE_ROTATION_RANGES=30.0 120 15
!====================== INDEXING PARAMETERS ===============
!Never forget to check this, since the default 0 0 0 is almost always correct!
!INDEX_ORIGIN= 0 0 0 ! used by "IDXREF" to add an index offset
!Additional parameters for fine tuning that rarely need to be changed
!INDEX_ERROR=0.05 INDEX_MAGNITUDE=8 INDEX_QUALITY=0.8
SEPMIN=4.0 ! default is 6 for other detectors
CLUSTER_RADIUS=2 ! default is 3 for other detectors
!MAXIMUM_ERROR_OF_SPOT_POSITION=3.0
!MAXIMUM_ERROR_OF_SPINDLE_POSITION=2.0
!MINIMUM_FRACTION_OF_INDEXED_SPOTS=0.5
!======= DECISION CONSTANTS FOR FINDING CRYSTAL SYMMETRY =========
!Decision constants for detection of lattice symmetry (IDXREF, CORRECT)
MAX_CELL_AXIS_ERROR=0.03 ! Maximum relative error in cell axes tolerated
MAX_CELL_ANGLE_ERROR=2.0 ! Maximum cell angle error tolerated
!Decision constants for detection of space group symmetry (CORRECT).
!Resolution range for accepting reflections for space group determination in
!the CORRECT step. It should cover a sufficient number of strong reflections.
TEST_RESOLUTION_RANGE=8.0 4.5
MIN_RFL_Rmeas= 50 ! Minimum #reflections needed for calculation of Rmeas
MAX_FAC_Rmeas=2.0 ! Sets an upper limit for acceptable Rmeas
!================= PARAMETERS CONTROLLING REFINEMENTS =========
!REFINE(IDXREF)=BEAM AXIS ORIENTATION CELL !DISTANCE
!REFINE(INTEGRATE)=!DISTANCE BEAM ORIENTATION CELL !AXIS
!REFINE(CORRECT)=DISTANCE BEAM ORIENTATION CELL AXIS
!================== CRITERIA FOR ACCEPTING REFLECTIONS =============
VALUE_RANGE_FOR_TRUSTED_DETECTOR_PIXELS= 6000 30000 !Used by DEFPIX
!for excluding shaded parts of the detector.
INCLUDE_RESOLUTION_RANGE=50.0 2.05 !Angstroem; used by DEFPIX,INTEGRATE,CORRECT 终末数据的最高分辨率。
!MINIMUM_ZETA=0.05 !Defines width of 'blind region' (XPLAN,INTEGRATE,CORRECT)
WFAC1=0.85 !This controls the number of rejected MISFITS in CORRECT; !a larger value leads to fewer rejections.
这一数值禁止rejection比率。1代表不遴荐rejection,一半在0.8-1.0之间。第一轮不遴荐rejection。最多不杰出10%的rejection,在输出的CORRECT.LP中的终末一个表格中不错算出rejection的比率。
!REJECT_ALIEN=20.0 ! Automatic rejection of very strong reflections
!============== INTEGRATION AND PEAK PROFILE PARAMETERS =========
!Specification of the peak profile parameters below overrides the automatic
!determination from the images
!Suggested values are listed near the end of INTEGRATE.LP这一数值INTEGRATE.LP中背面的表格能找到。上一轮的输出看成下一轮的输入。
BEAM_DIVERGENCE= 0.33031 BEAM_DIVERGENCE_E.S.D.= 0.03303
REFLECTING_RANGE= 1.02947 REFLECTING_RANGE_E.S.D.= 0.14707
对XDS.INP进行修改后,保存。然后实践多任务。在terminal输入小写的敕令
>xds_par
如果顺利,会完成。如果有错,会输出罪戾信息。需要重新对XDS.INP进行修改。
掀开三个文献:INTEGRATE.LP,CORRECT.LP,XDS.INP
根据前两者的输出,再放到后者看成下一轮的输入,然后轮回,直到REFLECTING_RANGE不变了,差未几10-20个轮回。
(1)在XDS.INP中输入正确的空间群和晶胞参数。
(2)将job改动为JOB = DEFPIX INTEGRATE CORRECT
(3)根据CORRECT.LP末尾的表格细目分辨率截断值。
(4)检察CORRECT.LP中的“alien”点列表,将它们放入其中以删除很是值
(5)REMOVE.HKL:awk'/ alien / {if(strtonm($ 5)> 20)print $ 0}'CORRECT.LP >> REMOVE.HKL
(6)将INTEGRATE.LP中的2行复制到XDS.INP的输入参数的建议值
*****为输入参数建议的值*****
BEAM_DIVERGENCE = 0.293 BEAM_DIVERGENCE_E.S.D.= 0.029
REFLECTING_RANGE = 1.473 REFLECTING_RANGE_E.S.D.= 0.210
(a)将GXPARM.XDS复制到XPARM.XDS并重新运行DEFPIX INTEGRATE和CORRECT
(b)看成终末的方法,将WFAC1从默许值1.0责怪到0.75,但要提神责怪的完整性和增多的R free!
(c)运行“xscale XSCALE.INP”进行扩张功课,并搜检日记文献“XSCALE.LP”
(d)提神三个轨范:最高分辨率壳层的完整性,I/sigma和CC1/2。
(e)不错忽略“R-meas和R-merge”(它们在高分辨率壳层中可能大于100%)。
(f)剪辑“XDSCONV.INP”,将数据格式转化为CCP4,CNS,SHELX。并运行“xdsconv XDSCONV.INP”。目前phenix不错平直把XDS输出的XSCALE.HKL文献转化成mtz文献。
(g)提神“REFLECTING_RANGE”是HKL2000的“Mosaicity”宗旨。
针对性建议(TROUBLESHOOTING)
1. 有的时候自动处理失败,主要照旧需要修改的参数,比如距离,角度,detector类型等莫得设好。
2. 偶尔是由于前边的衍射图不好,不错选背面的。
3. 如果redundancy足够,不错尝试扔掉背面部分衍射较差的数据,擢升分辨率。还不错稳妥责怪WFAC1。
4. 如果第一轮自动处理,细目空间群,但莫得进一步integrate。如果对空间群有信心,不如一经在HKL2000处理了。不错强制插足integrate。
5. XDS选点更多,因此数据质地比HKL2000更好,特别是高分辨率,强度较低的点,能够被领受。因此不错用HKL2000初步处理,终末用XDS处理。
5.9 XDS-J Version Theta简介(INTRODUCTION)
XDS-J是程金博2017年为XDS写的一个图形化界面(GUI)。本说明针对版块测试版Theta. 问题意见及建议请反馈至knight3a@mail.ustc.edu.cn。
XDS-J是XDS的图形用户界面。它使得X射线衍射数据的处理愈加容易和方便。XDS-J不错使大多数过程自动化,提供统计数据并裁汰处理数据所破耗的时期。简而言之,XDS-J对于XDS的新老用户来说齐是一个很有用的用具。
XDS-J由中国科学工夫大学结构免疫学实验室的程金博开发。商量方式:knight3a@mail.ustc.edu.cn
推选屏幕分辨率1280×960,分辨率过低会导致界面不完全傲气(界面上方和右方有滚动条)
系统要求(SOFTWARE REQUIREMENT)
Linux System (tested: CentOS 6.9, Ubuntu 16.04)
XDS (download from -heidelberg.mpg.de/html_doc/downloading.html)
xds-viewer
Python (tested: 2.7, 3.4) with module Tkinter and matplotli
XDS-J (version: open theta, last updated: 2017/07/04)
软件安装(INSTALLATION INSTRUCTIONS)
安装XDS:
下载,解压缩并确立PATH环境变量
安装xds-viewer:
迁移到PATH变量中的目次,例如XDS的安装旅途
$ wget ftp://turn5.biologie.uni-konstanz.de/pub/xds-viewer-0.6.64bit -O xds-viewer
$ chmod a+x xds-viewer
安装Python:
在Ubuntu下为python2安装模块Tkinter和matplotlib:
$ sudo apt-get install python-tk python-matplotlib
在Ubuntu下为python3安装模块Tkinter和matplotlib:
$ sudo apt-get install python3-tk python3-matplotlib
安装XDS:
解压缩并将实践文献XDS-J复制到PATH变量中的目次
基本使用格式(PROCEDURE)
1. 掀开末端,转到责任旅途后,键入敕令XDS-J。
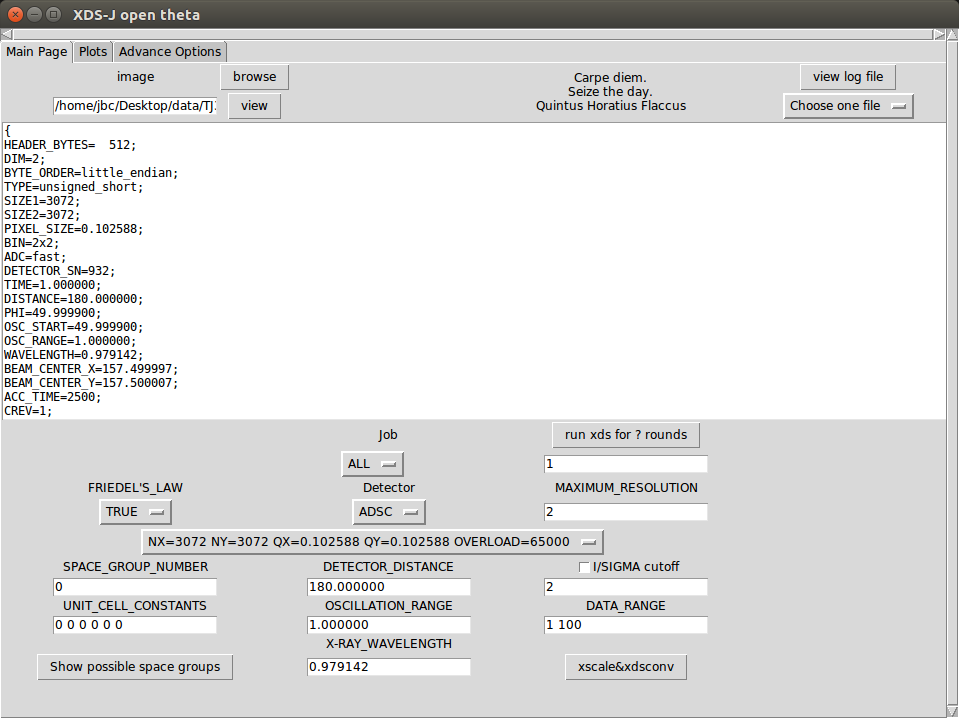
2. 通过image右侧的browse及第一张图片(不错不是第一张)(图片定名方式必须像如下几种这样:ab0001 ab_1_0001 ab_1.0001,不错带格式后缀,不错是压缩文献)(点击view不错不雅察图片)。
3. 取舍探伤器类型和参数,若参数不在列表中不错选other然后输入。某些探伤器不错自动读取。
4. 输入纪律运行所需其它参数或修改自动读取的参数(FRIEDEL'S_LAW在有重原子的时候应为FALSE)。
5. 点击run xds for ? rounds(不错不才面输入预备连气儿运行的轮数)。若纪律正常运行,杀青后会傲气红字Finished,斥逐会傲气在框中,自动细目的晶体类型和参数自动填入SPACE_GROUP_NUMBER和UNIT_CELL_CONSTANTS的框中。
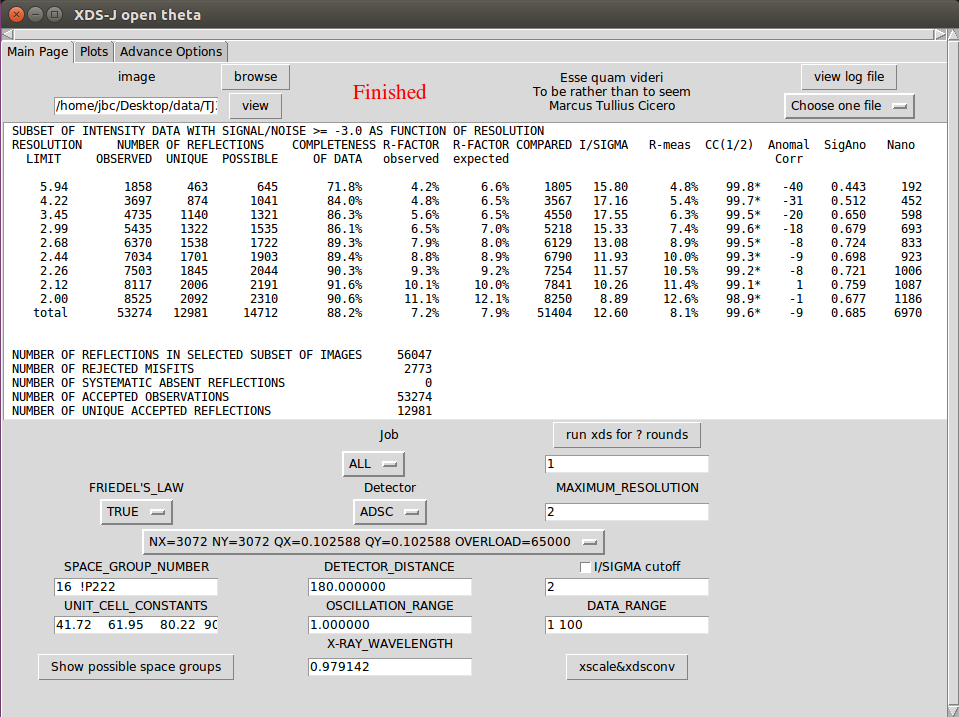
6. 一般Job前两次运行时选“ALL”,之后修改Job为'DEFPIX INTEGRATE CORRECT',根据斥逐修改最高分辨率(如果在I/SIGMA cutoff前边打勾,运行一次后剧本将根据输入的截断值自动细目上次使用的最高分辨率),也可修改其他参数(如DATA_RANGE,由于辐照挫伤有时候要铁心背面的数据,可参考第二页的图表,或者确立WFAC1 0.85~0.95,EXCLUDE_DATA_RANGE),点击xds再次运行。
7. 屡次重复运行XDS以优化斥逐。
8. 一般最终使最高分辨率对应的I/SIGMA接近2,CC(1/2)大于60,同期总的COMPLETENESS大于90%,NUMBER OF REFLECTIONS中的OBSERVED是UNIQUE的五倍以上,NUMBER OF REJECTED MISFITS小于NUMBER OF REFLECTIONS IN SELECTED SUBSET OF IMAGES的5%(以上数字仅供参考,并不完全)
9. 点击xscale&xdsconv,在弹出窗口中点击xscale(如果有多套数据,可在此步把它们合并)。再点击xdsconv,最终身成CCP4,CNS,SHELX可用的mtz文献。

其它功能(OTHER FUNCTIONS)
1. 在界面右上角不错取舍一个日记文献,然后点击view log file按钮掀开检察。
2. 点击Generate XDS.INP only按钮将只生成XDS.INP文献而不运行xds。
3. 点击View XDS.INP按钮可检察XDS.INP文献,改动内容后点击save不错保存。
4. 如果想专揽已有的XDS.INP文献运行则点击Run with existing XDS.INP按钮。
5. SPACE_GROUP_NUMBER为0时运行完xds点击Show all possible space group按钮可傲气CORRECT.LP文献中判断的整个可能的空间群及参数。
提神
(1)XDS在积分时着力优于其他软件,但有时自动细目的空间群不准确。这时不错先用其他软件(例如HKL-2000,iMOSFLM)细目空间群,再用得到的参数运行XDS。
(2)运行XDS时整个这个词界面将暂时处于锁定状态,不要对其进行任何操作,以免形成未知后果。
(3)纪律运行时将产生好多文献,最好在一个单独目次下运行。
(4)傲气斥逐的最大分辨率与输入的最大分辨率不一致可能是因为改分辨率下莫得点。
(5)如果斥逐傲气各个分辨率鸿沟的信噪比齐很低且别离较小,有可能是晶体位置(ORGX,ORGY)偏离较大或空间群取舍罪戾。
(6)运行失败可能的原因包括:数据自己质地不好(可通过view按钮检察图片),旋转轴的正负罪戾,最高分辨率过低(例如0),空间群取舍罪戾(改变DATA_RANGE有可能导致自动细目的空间群不同)。
6. 擢升信噪比喻法:WAC1调低(如0.8,0.9),改变DATA_RANGE,多运行几轮XDS。
7. 探伤器类型和参数未知的不错尝试通过读取图片的文献头中的信息再加上用xds-viewer掀开细目像素,再参考XDS网站得到。关系参数可在XDS网站(-heidelberg.mpg.de/html_doc/detectors.html)上找。
参数的意旨
(详备先容参见-heidelberg.mpg.de/html_doc/xds_parameters.html)
1. Job为All时将运行XYCORR,INIT,COLSPOT,IDXREF,DEFPIX,XPLAN,INTEGRATE,CORRECT
2. MAXIMUM_NUMBER_OF_PROCESSORS为要使用的处理器数,最大32。
3. DETECTOR,NX,NY,QX,QY,OVERLOAD为探伤器的参数。
4. ORGX,ORGY为晶体所在位置,默许为NX,NY的一半,特殊情况晶体偏离中心可通过不雅察图片后输入。
5. RESOLUTION填最大分辨率(单元A)。
6. NAME_TEMPLATE_OF_DATA_FRAMES为图片所在旅途,提神不可有空格,例如/test/TJ_1_???.img以走漏TJ_1_001.img,TJ_1_002.img,TJ_1_003.img等。
7. DATA_RANGE为要使用的图片鸿沟,填两个整数,以空格离隔。
8. ROTATION_AXIS一般为1 0 0(但18u,19u是-1 0 0)。
10. SPACE_GROUP_NUMBER第一次运行不知说念的话填0,此时UNIT_CELL_CONSTANTS不错空着,XDS不错自动细目空间群,不外有可能不正确。
11. TRUSTED_REGION如果是0到1特别于探伤器的内接圆,0到1.414特别于探伤器的外切圆。
12. WFAC1值越小,拒却的点越多,一般在0.8~1.0之间。
13. FRIEDEL'S_LAW在有重离子的时候应为FALSE。
14. EXCLUDE_DATA_RANGE是要排除的数据鸿沟,两个整数用空格离隔,如要排除单张则两个疏导数字,该参数不错有多行。
剧本运行旨趣
1. 通过image右侧的browse及第一张图片会傲气图片的头几行,剧本自动细目NAME_TEMPLATE_OF_DATA_FRAMES,DATA_RANGE为所独特据,并从中读取DETECTOR_DISTANCE,OSCILLATION_RANGE,X-RAY_WAVELENGTH等参数(目前只救济ADSC,PILATUS,CCDCHESS三种探伤器)。
2. 点击view将调用xds-viewer掀开及第的图片。
3. 点击run xds for ? rounds,剧本将自动生成XDS.INP并运行xds_par。若纪律正常运行,杀青后会傲气红字Finished,CORRECT.LP中的斥逐会傲气在右侧的框,取得的晶体类型和参数自动填入SPACE_GROUP_NUMBER和UNIT_CELL_CONSTANTS的框中。
4. 如果在I/SIGMA cutoff前边打勾,下次运行后剧本将根据输入的截断值通过线性插值法估量下次使用的最高分辨率。
5. 点击run xds for ? rounds再次运行时剧本会自动读取INTEGRATE.LP中REFLECTING_RANGE,REFLECTING_RANGE_E.S.D.,BEAM_DIVERGENCE,BEAM_DIVERGENCE_E.S.D.的值加入XDS.INP文献中,并用GXPARM.XDS替换XPARM.XDS。
6. 点击xscale时,剧本自动生成XSCALE.INP并运行xscale。点击xdsconv时,剧本自动生成XDSCONV.INP并运行xdsconv,f2mtz。
5.10 分子置换法解相位 简介(INTRODUCTION)分子置换(MR)是最常用的科罚相位问题的方法。一般要求主见卵白A有同源卵白结构B,同源性30%以上。
实验格式(PROCEDURE)
(1)先用CCP4中的matthews判断一下一个晶胞中有些许个分子。在CCP4 MR 模块下,掀开cell content analysis。 这个是晶体中卵白集合体数的分析,通过分析晶体含水量得到一个晶胞内的卵白分子数。需要输入mtz文献,单体卵白的分子量或者氨基酸数量。由于大多数生物大分子晶体含水量在40%~60%之间,同期最小对称单元中,卵白数值对应n是整数。不错初步细目n值。这个集合体数n会在mr中使用,用来愈加准备估量含水量看成配景。一般分辨率在2埃的晶体其含水量在50%摆布。也不错根据分辨率,率领n值的细目。
(2)格式:输入mtz文献,再不才拉菜单中取舍一种细目分子量的方法。可平直输入(默许)或用残基数,序列文献,pdb文献估量等。点击Run Now。运行完成后得到不同分子数(Nmol/asym)对应的可能性(P(tot))。一般会有一个数字对应的可能性相配大,即一个晶胞中的分子数。
(3)model 及第:进行分子置换的model为已知的同源卵白结构或硒代得到的pdb,对model的要求是越接近球形越好。一般用单体。从pdb库中下载了pdb后不错用vim剪辑,及第我方想要的那一段作念model。
(4)Phaser MR作念分子置换。该纪律在CCP4和Phenix中齐有。
(5)使用CCP4格式:
整个必须项齐用深黄色标示出来了。在Define Data栏中及第mtz文献,如果不细目空间群不错把Run Phaser with后的下拉菜单选成all alternative space groups。在Define ensembles栏中及第pdb文献。在Define composition of the asymmetric unit栏中及第序列文献(可用输入分子量或输入残基数代替),Number in asymmetric unit背面输入之前得到的晶胞等分子数。点击Run Now。
(6)使用Phenix格式:
在Input and general options页中及第mtz文献。在Ensembles页中点击Add file及第pdb文献。在ASU contents页中及第序列文献(可用输入分子量或输入残基数代替)。在Search procedure页中点击Component 1后的按钮Add ensemble中选之前添加的阿谁pdb文献,Copies to search for填之前得到的晶胞等分子数,如果不细目空间群不错把Also try alternative space group选成All possible in same pointgroup。点击Run。
(7)见效运行会输出一个mtz文献和一个pdb文献。
重要格式:
如何判断得到的解是否正确。TFZ大于8走漏简直不错细目是正确的解,7~8走漏很有可能,6~7走漏有可能,5~6走漏不大可能,小于5走漏不可能。PAK渴望情况为0。
如果见效找到解,接下来就不错进行结构修正。
可使用CCP4中的refmac5或Phenix中的phinex.refine。把之前得到的mtz文献和pdb文献看成输入,运行见效会输出一个mtz文献和一个pdb文献。运行前后Rfree,R-factor的值应该有所减少。接下来用COOT同期载入刚才输出的两个文献,手工进行结构修正。然后再用纪律进行修正,赓续重复这一步。见背面Coot指南。
如果领导mtz文献莫得Rfree标签,掀开CCP4中的truncate。及第该mtz文献,选中Ensure unique data & add FreeR…。点击Run Now。输出文献就有了。
5.11 结构优化搜检清单简介(INTRODUCTION)
结构修正永久不会完成,但是当东说念主们再也无法立异时,就无须再修正了。以下是我的搜检清单,您无需按照订单操作。

实验格式(PROCEDURE)
1. 确保模子的序列是卵白质的履行序列。使用Phenix或其他用具索取最终模子的序列,并与您的履行卵白质序列进行序列比对(根据您的测序斥逐)。
2. 在coot中搜检map和模子。
(1)手动搜检2Fo-Fc图谱中5 sigma以上的峰值。
(2)莫得未建模的雀斑。
(3)莫得ramachandran plot outliers。接力改善它。
(4)搜检并开垦大多数侧链outliers。
(5)仔细搜检结构中的任何配体。
(6)搜检水。去除那些密度很弱,即小于11 sigma峰值的那些,以及那些与其他原子距离太近(小于2.2 Å)或太远(大于3.5 Å)的水。
3. 在Phenix.refine中,使用TLS修正。简直在职何分辨率下齐很好。
4. 在phenix.refine中,在修正中使用氢不错改善突破。唯有在相配高的分辨率下(即高于1.5Å)使用氢,否则使用riding模子。
5. 手动或自动优化X射线/立体化学,ADP分量。
6. 你的修正敛迹,与相似分辨率鸿沟内的结构比拟,R因子变化不大且合理。Rfree和Rwork之间的差距小于5%。
7. 搜检phenix.refine中MolProbity的输出,并开垦任何问题。
8. 提交考据行状器或存储行状器。
5.12 如何修正低分辨率的结构(5-6 Å)简介(INTRODUCTION)
不同分辨率,结构的修正难度别离很大。分辨率低预示着来自数据的信息少,数据比参数的比值低,结构不细目性大。而最基本的,岂论奈何修正,结构的整个键长键角等数值不可抵触表面值。
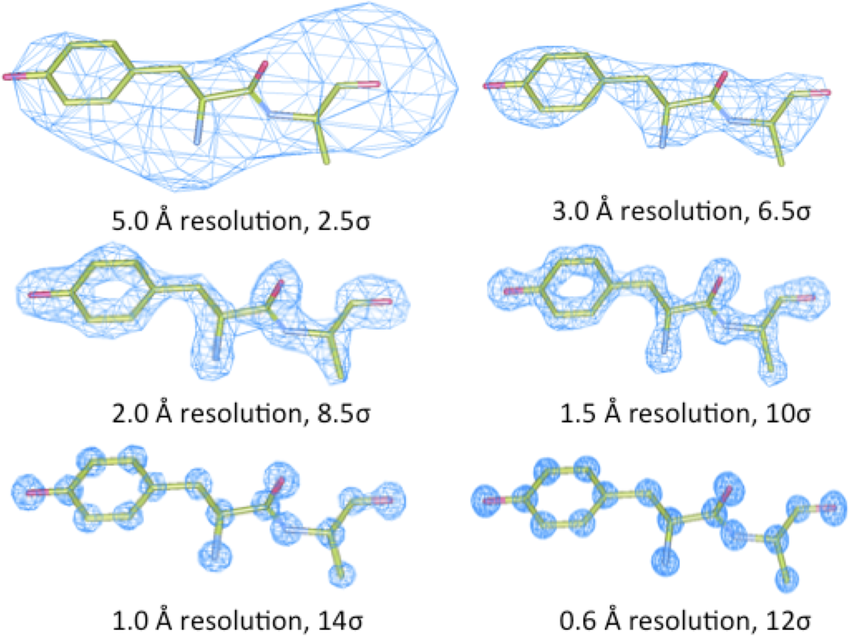
教程 (TUTORIAL)
东说念主们频繁使用Phenix.refine来修正低分辨率结构,因为phenix.refine履行上是一个很好的纪律,不错针对低分辨率结构进行细化。如何进行取决于您但愿完成细化的内容。如果结构一经近似正确,莫得要紧的构象变化,这里有一些基本的率领原则:
1. 使用紧赓续。权重自动优化在此分辨率鸿沟内不可很好地责任,因此不错同期将wxc_scale和wxu_scale确立为相配低的值(它禁止X射线项相对于几何和B因子料理的权重) 是一个很好的起初。建议尝试wxc_scale = 0.025和wxu_scale = 0.05的值。
2. 如果ASU中有多个分子,请使用NCS限制(torsion限制广泛是足够的,况兼更容易使用,但也可能值得尝试cartesian限制)。
3. 如果你有一个好的高分辨率结构,不错使用参考模子(这可能仅仅结构的一部分)。
4. 真实空间的修正可能不会起作用。
5. 起初尝试使用相配保守的修正政策,例如刚体和B族因子簇修正。后者可能着力更好,因为增多了对邻近基团的限制。您还不错尝试优化结构域TLS。我我方的教会是,individual coordinate和 B-factor refinement的立异着力最好。后者有点争议,但是在严格限制的情况下,它最终与修正举座B因子莫得太大区别。在修正开始时将整个B因子重置为20有助于摈斥肇始模子的偏差。
6. 在此分辨率下应该对于2mFo-DFc电子云图相配严慎,它看起来简直就像你的模子。因此需要制作普遍的Omit电子云图,如果你有任何重的散射体(金属等),这些将相配有助于阐发你结构的正确性。如果你真的需要进行普遍的重建,那就更难了,DEN或Rosetta修正可能会有所匡助。
7. 界说二级结构并在结构修正中使用它。如果不使用二级结构限制,那么在肇始模子中即即是渴望的二级结构在如斯低分辨率的修正之后也会恶化。最病笃的是,确保您界说的二级结构限制履行上用于修正。您不错使用phenix.secondary_structure_restraints让Phenix自动识别二级结构。至关病笃的是,您需要手动检察它,并在必要时进行剪辑(最有可能的情况),以取得最准确的详细!
8. 旋转NCS在大多数情况下是比较好的取舍,然后在相配低的分辨率下,笛卡尔NCS可能是更好的取舍。因此,正如纳专指出的那样,尝试两者并望望哪一种着力最好。
9. 如确凿实空间修正推崇欠安,请禀报罪戾,因为它将摈斥旋转很是值rotamer outliers。
10. 如果有Ramachandran outlier拉氏图很是值:手动固定它们,然后使用Ramachandran plot restraints来防护它们再次发生(病笃:不要使用拉氏图限制来开垦很是值!)。
11. 如果数据集严重不完整,请检察两个2mFo-DFc舆图:旧例和缺失Fobs“已填充”(phenix.refine输出两个舆图)。
露出porn 5.13 结构认识软件的使用 5.13.1 HKL2000 基本操作简介(INTRODUCTION)
这部分简要先容如何使用HKL2000软件处理卵白晶体衍射数据。由于篇幅的限制,这里很少触及每个参数的具体意旨。
实验格式(PROCEDURE)
1. 掀开“HKL2000”软件并加载衍射数据
(1)点击鼠标右键,在菜单中取舍“open terminal”或平直点击末端窗口掀开末端窗口。在末端窗口输入“HKL2000”→Enter。此时就掀开了HKL2000纪律。
(2)掀开HKL2000纪律之后会自动出现一个对话框,让你从菜单中取舍检测器。每个线站的检测器类型不才表中列出,选过之后点击“OK”按钮。

线站
17U1
18U1
19U1
19U2
Detector
Eiger X 16 M
Pilatus6m
Pilatus6m
Pilatus1m
衍射仪
MD2
MD2
MD2
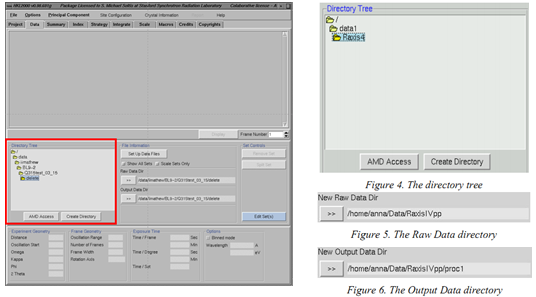
(3)此时HKL2000的主窗口会掀开。插足“DATA”页面,在左侧的“directory tree”中找到你要处理数据所在的文献夹(你的衍射图片不会傲气出来,并不是你的文献夹是空的)→点击“Create Directory”→在新出现窗口的输入面板后加上“/hkl”→点击“create”(创建一个名为“hkl”的子文献夹,用于存放处理产生的新文献),将你的衍射数据所在的文献夹确立为“Raw DATA Dir”、新创建的“hkl”文献夹确立为“Output DATA” (不需要东说念主工输入,点击相应的文献夹之后再点击![]() 即可)
即可)
(4)Figure 6 是将子文献夹定名为“proc1”
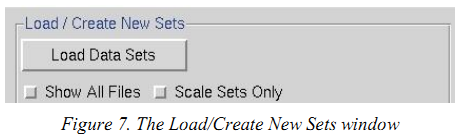
(5)点击“Load Data Sets”取舍你要处理的数据(会变蓝),点击“OK”
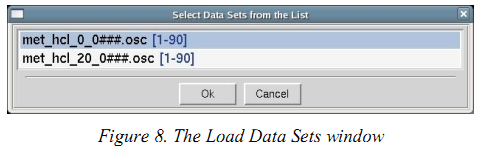
会出现一个新窗口,如下图。如果跳出来一个新窗口点击“continue”

备注:figure 7 的“Scale Sets Only”是只傲气index和integrate之后的文献,是以对于只需要scale处理的数据不错勾选。
(6)如果你的数据有些衍射不好或其他原因需要丢弃,不错点击set controls中的“splict set”将不要的数据抛弃掉。

2. Index和refine
(1)插足Index 界面,填写分辨率,将3Dwindow 填写为“5”、display Frame Number一定要填写为“1”。点击“display”之后会出现一个display窗口。点击index界面的 “Peak search”按钮。用鼠标中键点击display窗口上的“Frame”5次,然后点击“OK”。
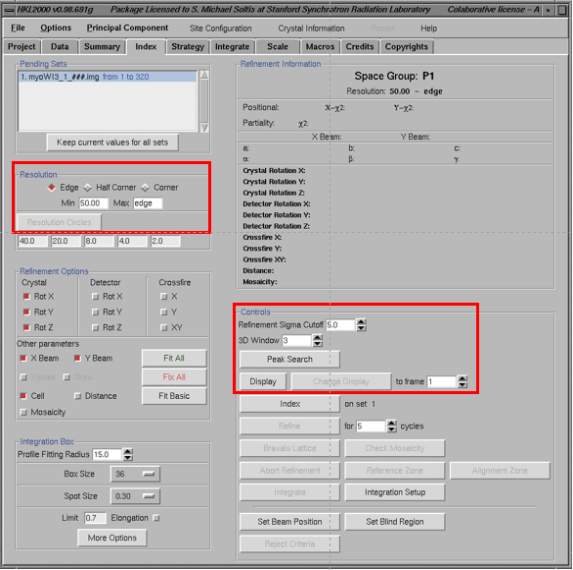

备注:分辨率奈何确立:如果有冰环存在的话就确立为4A。
3D window奈何确立:3Dwindow的数值乘以单张摇荡角角度至少是优化后嵌入度的两倍,对卵白晶体,5是一个比较合理的数值
(2)点击index窗口的“index”按钮以启动index纪律→点击“Bravais table”出现Bravais table窗口,取舍“primitive triclinic ”晶格→点击“apply & close”。在display 窗口阐发绿色的预测环与衍射点要重合的比较好


(3)Index之后,点击“refine”按钮,refine第一轮之后将refinement options选为“Fit All”再次点击“refine”按钮。提神不雅察X-X2、Y-X2的值(最好不要杰出2,如果绿色的预测环与衍射点重合的比较好的话也不错)→再次点击“bravais lattice table”取舍合适的晶格(绿色的)→apply &close→refine。建议从低对称性往高对称性挨个往上走,这是多个refine的轮回。

备注:如果预测环与衍射点不合适的话,可能暗意你的晶格类型选错了
X2是计算预测环与衍射点拟合过错的参数,但是这个数值对于index和背面的integrate影响不大。
3. 确立分辨率、Fitting Radius 和 Spot Size
(1)如何确立spot size
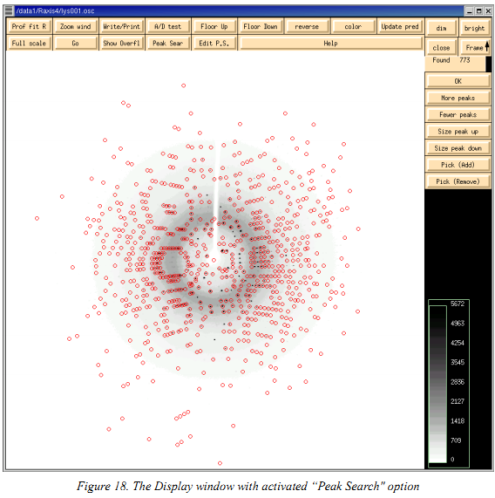
取舍太小的spot size,则有些衍射点会被丢耗费,太大的spot size会使衍射点重复,而重复的衍射点在scale时会被reject且在筹办衍射点的intensity时会将周边衍射点的强度也筹办进去。
由于衍射点自己的大小就不长入,是以就要作念一个衡量,一般的教会律例是尝试调治spot时势以稳妥图像上的某些中等的点到强点。
(2)如何确立分辨率
一般来讲,要将分辨率确立为比你看到的稍稍好一丝,这样即使你确立的分歧理还不错在scale时改正过来。相背,如果分辨率确立的保守了,你将不得不在scale之后复返来重新integrate,因为scale并不可使用杰出你目前设定的分辨率。细目好分辨率之后,你需要再复返index窗口重新填写分辨率。然后再次refine。这相通是个反复的过程。
(3)如何确立Fitting Radius
Profile Fitting Radius is used to calculate the average spot profile,Generally, the radius is set so those spots on roughly 3~5% of the area of the detector are included in the averaging
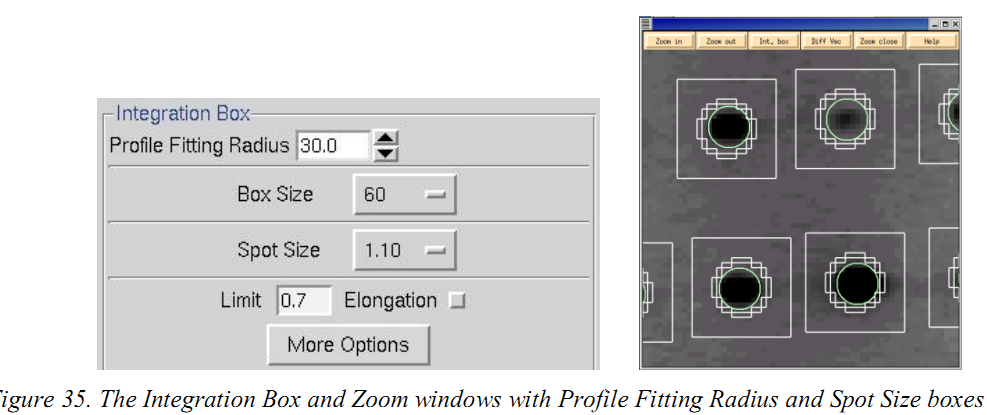
(4)Elongation Limit是什么?
这个选项是商量到由X射线与探伤器在高角度交点引起的雀斑的径向伸长。 通过点击 “Integration Box”面板中的“Elongation Limit”按钮激活此功能。 Elongation Limit的默许值(走漏为spot伸长率的分数)是0.7。鸿沟从0到1。
4. 3D Window 和 嵌入度
(1)什么是3D Window
3D窗口是同期进行integrate的连气儿image的数量。该功能的一个主要优点是将image合并在全部不错在refine中包括更多的衍射点,从而擢升index的准确性。

(2)如何确立嵌入度
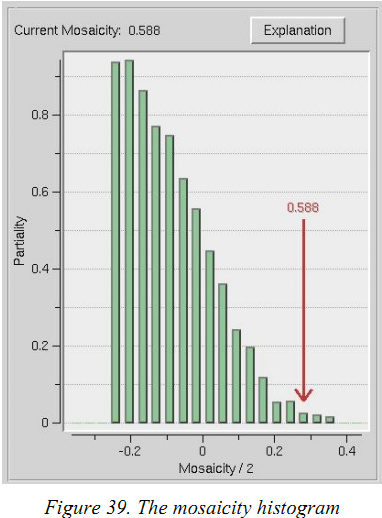
确立嵌入度的最好方法是使用3Dwindow,在integrate衍射点时对嵌入度进行refine。正确确立嵌入度并不总会导致预测环掩盖image上的整个衍射点。特别是,相配强的low order的衍射点可能需要特别大的嵌入度值才气被预测环掩盖。这些衍射点可能不代表晶体内在嵌入扩散,可能是由于该晶格点的特别历害的衍射产生的。你点击“Crystal Information”按钮并输入“嵌入度”,教会上讲嵌入度确立得高比确立得低好,但确立的太高可能会导致普遍的overlap。
5. Strategy and Simulation(不属于数据处理过程)
(1)Strategy and Simulation的目的是用来决策什么样的参数(曝光时期、距离、摇荡角、网罗度数)不错得到比较好的晶体数据。
(2)奈何开始政策?
正常Index之后,在细目正确的晶格、稳妥的分辨率、选fit all refine后,先别开始intergrate。
一朝index之后,插足strategy界面(图41),第一个表就是strategy,点击strategy左侧的“strategy”按钮→出现含好多彩线的图(横坐标omega (Kappa, Chi, Phi)start就是开始角度,,纵坐标delta Omega是总度数)。

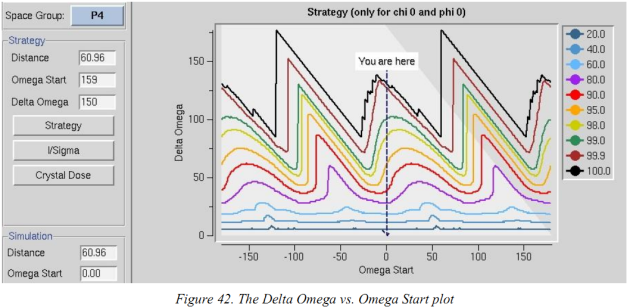
是以Delta Omega vs. Omega(Kappa, Chi, Phi) Start描摹的是在某一给定的肇始角度要网罗相应百分比的数据(彩色线)所需的最少度数(灰色三角部分是由于硬件限制不可网罗的区域)。将鼠标迁移在窗口中左侧傲气出Omega Start and Delta Omega。是以玄色线的最低端的Delta Omega是网罗100%数据所需的最少度数,但要从相应位置开始。建议网罗360(对称性越高所需度数越少)→点击鼠标,相应的位置的Delta Omega 、Omega Start会填入Simulation面板中→点击“simulate run”出现一个新窗口

用于预测数据网罗过程中overlap衍射点的数量。当晶体具有高嵌入性或长晶胞轴的时候这很病笃,这两种情况使部分image中的衍射点出现严重重复而无法使用(当长晶轴平行于光束时会overlap)。
你不错改图左侧的frame width的值,然后重新“simulation run”(减少frame width的值overlap应该也减少,因为总的点少了),想增多完全记录的衍射点的百分比则增多摇荡角。对于overlap比较高的情况,也不错增多距离然后再次SIMULATE RUN,衍射点会分的更开但最高分辨率会低。
上头的四个参数(开始角度、总角度、距离、摇荡角)细目之后,就不错用这些参数来收数据了。
6. Integration and scale
(1)点击index界面的integration按钮, X2,Cell Constants,Crystal Rotations,Mosaicity和Distance vs。 Frame图表的线齐应该是水平的,X2vs. Frame 的两条线齐应该在1~2之间。

(2)Integration按钮是红的或橙色说明什么
X2值太大,高嵌入性等导致的,不错尝试re-index。尤其是当晶胞参数变化大时,不错点击“fix mosaicity”这是因为当多晶存在时纪律不知说念选哪些,但限制了嵌入性就限制了点。或者就是点阵选错了。
7. Scaling
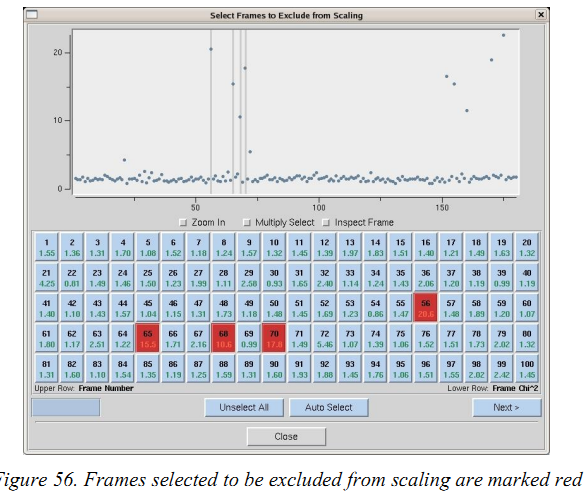
(1)在integrate之后,某些image可能在integrate信息图中具有相配高的碎裂值。 您不错通过单击EXCLUDE FRAMES按钮从scale中去除这些image。 将出现一个包含image列表的表格。 通过点击image的框或者通过点击“Multiple Select”取舍一定鸿沟的image(一次点起首,一次点斥逐)。 红色标记的image将被去除。然后关闭表格并重新scale。
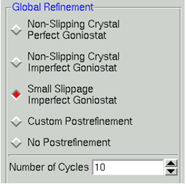
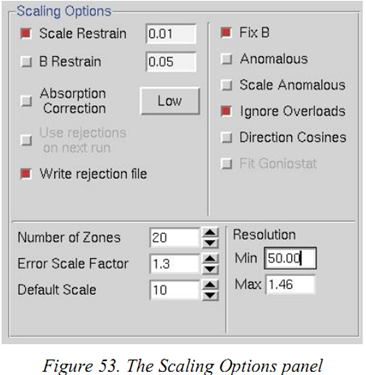
(2)插足“Scaling”界面。取舍合适的“Global Refinement”选项(5个选项,最好取舍Small Slippage Imperfect Goniostat),填写scaling options里的值
Scaling options 选项框的默许值:Scale Restrain 0.01,B restrain 0.1,选Write Rejection File,选Ignore Overloads,Number of Zones 10,Error Scale Factor 1.3,Default Scale 10、分辨率限制是从.X file读出来的(index和integration之后的值),最好选上“Absorption correction”。
(3)先选primary空间群(布拉维点阵的第一个空间群), 点击“scale sets”开始第一轮scaling,提神X2的统计数据。
(4)第一轮scale之后,搜检输出图表并调治“error scale factor”(使X2到1)、然后点击delete reject file,再次点击scale sets。重复这些格式直到举座X2可给与,然后通过选上“Use rejections on Next Run”接续后继的scaling,再次scale。重复scaling和rejecting的轮回,直到新拒却的数量一经下跌到唯有几个。 此时scale就完成了。选过“Use rejections in next run”之后根据2σ调治分辨率

(5)下一轮的scale填入的最高分辨率要比信噪比大于2的稍好一丝。比如:起初分辨率为50-2.2,第一轮scale后,发现I/sigma=2在2.3A处。是以下一轮分辨率为50-2.3.
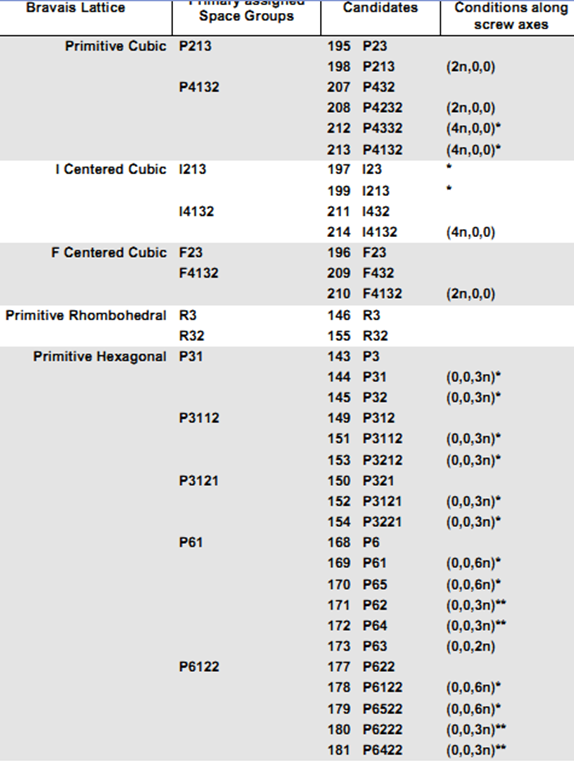
(6)目前尝试更高的对称空间群(下一个)并重复scale,保捏其他整个内容疏导。如果X2大致不变,你不错接续。如果X2更厄运,那么这是罪戾的空间群,上一个取舍是你的空间群。但有个例外,对于primitive Hexagonal点阵,在P3121 and P3112失败后要尝试P61

提神:标星号的是相似的空间群,衍射强度的scaling和merge不可科罚你的晶体属于哪个空间群。
(7)掀开log.file的最下端(点show log file)或模拟的倒易点阵图(点RECIPROCAL LATTICE)搜检系统消光。如果空间群是对的,则系统消光的衍射点应该不存在(或很小)。将该列表与其他候选空间群的衍射点条件列表对比,如果你的数据中消光的部分和哪个空间群消光特征一样则这就是你的空间群。
(8)如果讲解你的空间群是orthorhombic(正交)的且包含一个或两个旋转轴,你需要reindex使旋转轴与轨范界说一样。如果唯有一个螺旋轴,你的空间群就是P2221(螺旋轴和c平行),如果有两个螺旋轴,你的空间群是P21212(螺旋轴along a和b)如果index的与这不符重新index吧(点击reindex)。
(9)Scale的输出文献
output.sca:包含scaled reflections(衍射点),晶格单元、space group和h、k、l、I、σ。不错重定名,但最好保留后缀“.sca”

scale.log:scaling 操作的log(记录)文献。不错重定名,但最好保留后缀“.log”
Scale.log是scalepack的log(记录)文献,包含整个读入的“.x”文献(index后的文献)每个scaling轮回的记录。不错用来搜检scaling的质地。
每个轮回之后齐应该搜检log文献,尤其是:errors、X2和两个R因子。在接近终末有“redundancy”
备注:
什么是Error Scale Factor以及奈何调治它?
ERROR SCALE FACTOR是一个单一的乘法因子,用于输入的。.它应该调治以使X2的值接近1。.默许情况下使用输入的过错(ERROR SCALE FACTOR = 1.3)。 默许值不错进取调如果X2大于1。
Error Scale Factor的合理值是什么?
合理的值介于1和2之间。默许值为1.3。 如果你需要使用开阔于2的值,那么就有问题了。
在scale后傲气的图表中应该寻找什么?
Scale杀青后会有10个chart,每个chart齐有说明按钮。有些chart有两个垂直轴,对应的线对应相应的轴,有些chart不错在线性和log图间转化。底下是几个例如:
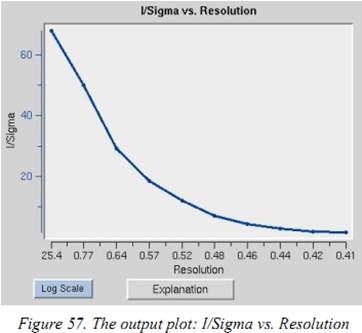
I/sigma vs resolution:I/sigma是intensity与过错的比值,在scale中应该取I/sigma为2的分辨率
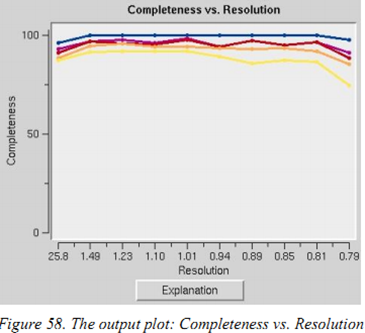
Completeness vs.Resolution:不同分辨率下数据的完整性,蓝线代表全部的衍射点、紫色的是I/σ大于3的衍射点、红色是大于5的、黄色是大于20等等。这一步不错判断你的网罗政策是否灵验,是否需要更多的数据。
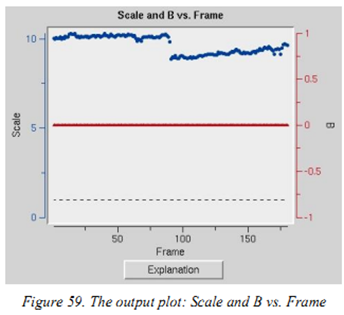
Scale and B vs. Frame:看images之间intensity和B因子是否有大的变化,用于判断晶体是否旋转出束或者受到辐照损害。
奈何处理含有反常信号的数据
检测是否含有反常信号相配容易:取舍“anomalous”选项(不是SCALE ANOMALOUS选项)后数据进行正常的scale和postrefine。这会输出I+和I-衍射点分开的.sca文献。Scale会将独处测量I+和I-数据,两者合并的统计数据反应出I+衍射点和I-衍射点的各别。对于中心部分的衍射点莫得I-,是以合并统计只会反应非中心的衍射点。你不错用于筹办合并统计的数据百分比通过搜检日记文献末尾隔邻的redundancy表格。在redundancy> 2的列,你将找到百分之些许的数据用于比较。因为你唯有I+和I-,是以redundancy永久不会杰出2。
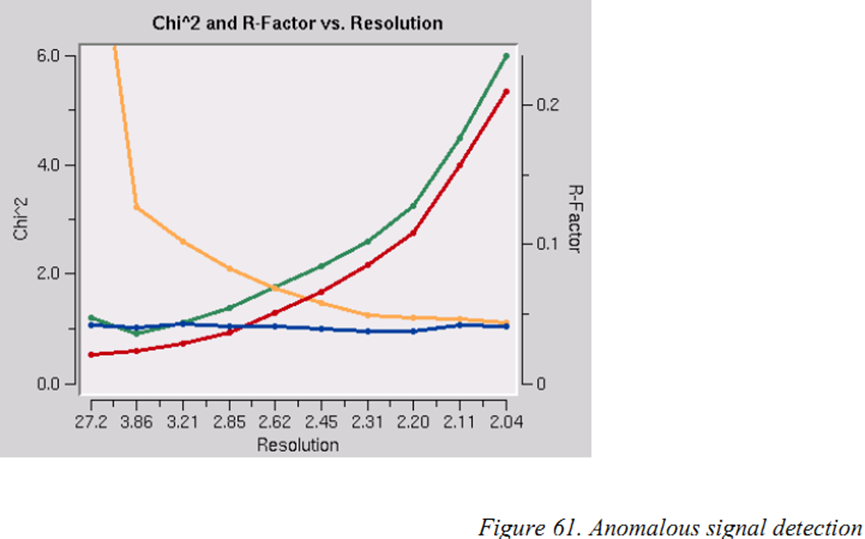
通过搜检Chi^2 and R-Factor vs. Resolution中的X2的值来检测很是信号的存在。
两条X2弧线傲气了分辨为合并的(橙色)和未合并的(蓝色)Friedel配对筹办的不同分辨率下X2的值。假设errors scale factors是合理的,况兼数据中莫得有用的反常信号,那么当使用合并或未合并的Friedel配对进行scale时,两条弧线傲气的X2对分辨率函数应该是平坦的且平均值约为1。另一方面,如果X2> 1且对于使用合并的Friedel配对进行的scale,X2具有清晰的分辨率依赖性(即跟着分辨率责怪X2增多),则历害标明存在反常信号。分辨率依赖性允许您细目在何处割断分辨率以筹办具有最好信噪比的反常各别帕特森map。但请提神,该分析假设罪戾模子为合理的且当反常信号不存在时X2接近1。
简介(INTRODUCTION)
CCP4英文全称为Collaborative Computational Project,Number 4。CCP4i是CCP4图形用户界面。
CCP4是晶体学软件开发方面的和谐,以分拨一套晶体学纪律和软件库而著名(Collaborative Computational Project,1994年第4期)。软件库救济一些轨范的晶体文献格式,并提供用于敕令认识,对称处理和其他常费事能的用具。主要用于X-ray衍射数据的处理,结构认识及分析。
操作格式(PROCEDURE)
举座先容
掀开CCP4i软件后,会出现如图 1所示界面。起初要确立project的称号及存储位置,本次例如的称号为“FXJ”。软件运行过程中需要的文献和输出的文献齐会在该project中。如图 2所示,常用的有5个模块:数据处理,分子置换认识结构,结构模子的修正,结构模子的分析及map关系操作。
图 1 CCP4i软件掀开后的界面
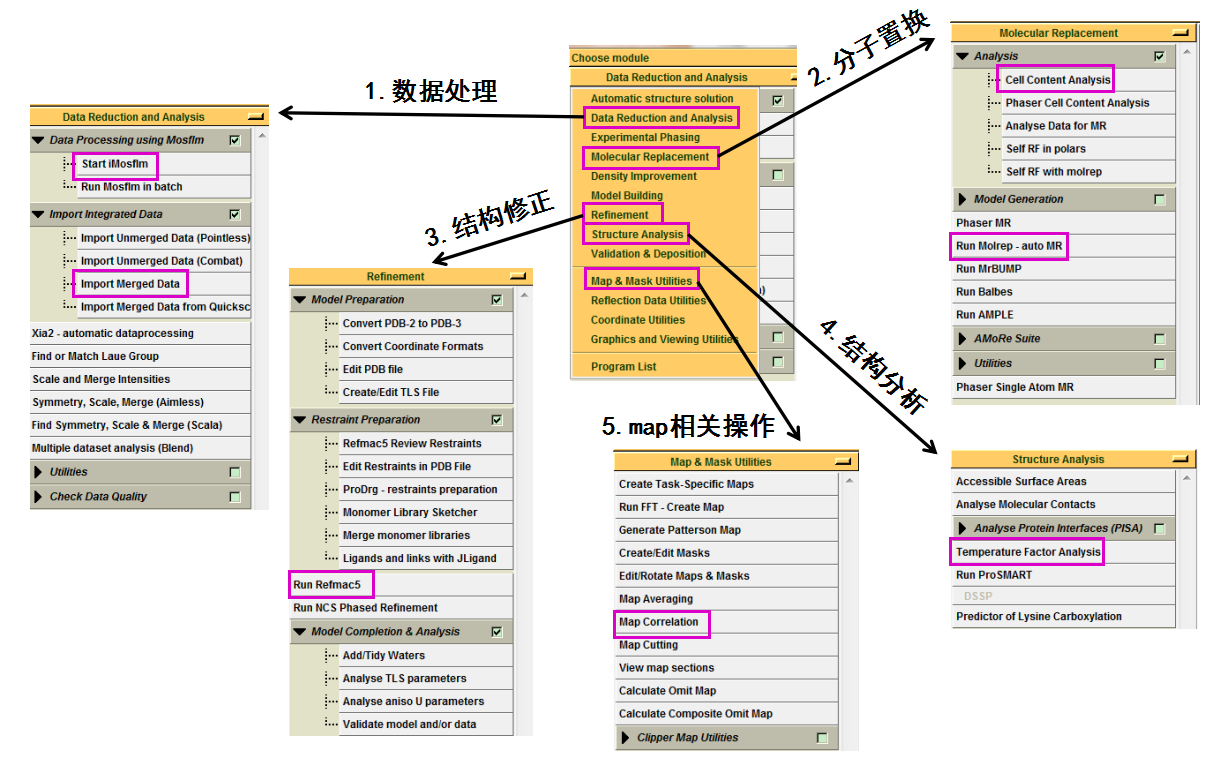
图 2 CCP4i软件中常用的5种模块
数据处理(一般无须iMosflm处理数据,苟简了解一下)
1. 先在“Data Reduction and Analysis”下拉菜单中点击“Start iMosflm”,接着会出现如图 3所示的界面。
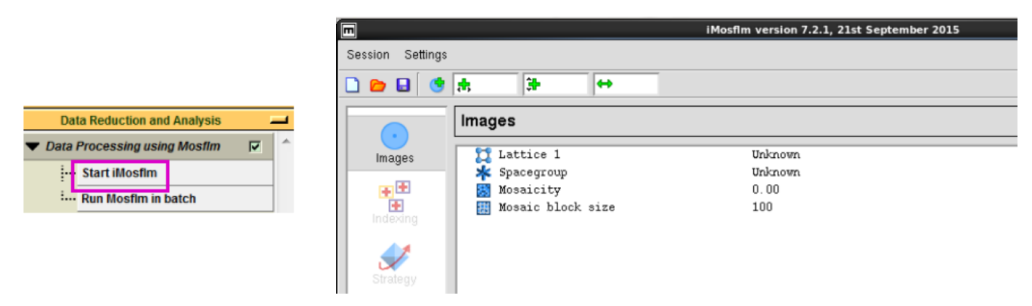
图 3 数据处理“Data Reduction and Analysis”界面
2. 点击图 4红框所示的图标,取舍要处理的衍射画面文献。
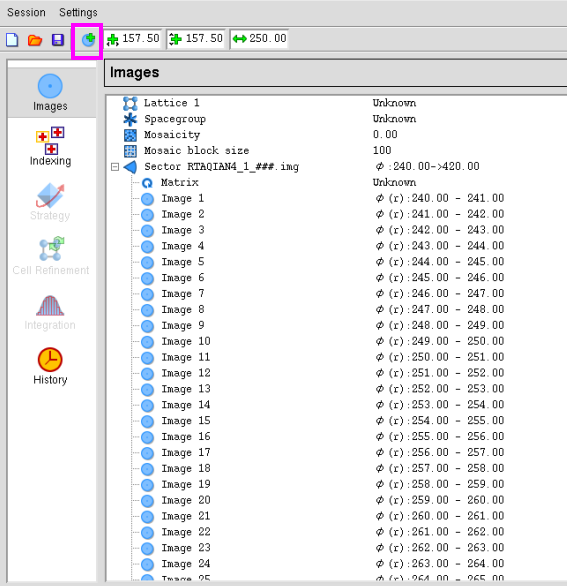
图 4 数据处理中衍射画面的输入
3. 点击图 5中的“Images”,不错检察衍射画面上衍射点的分辨率及衍射点的质地。
图 5 数据处理中衍射画面的检察
4. 点击“Indexing”,不错对衍射画面进行目的化(图 6图 7)。
图 6 数据处理中Indexing界面
图 7 数据处理中Index过程
5. 在“Strategy”中不错检察参数(图 8)。

图 8 数据处理中“Strategy”界面
6. 在“Cell Refinement”中不错确立一些参数进行修正(图 9)。
图 9 数据处理中Cell Refinement界面
7. 点击“Intergration”进行强度积分(图 10)。
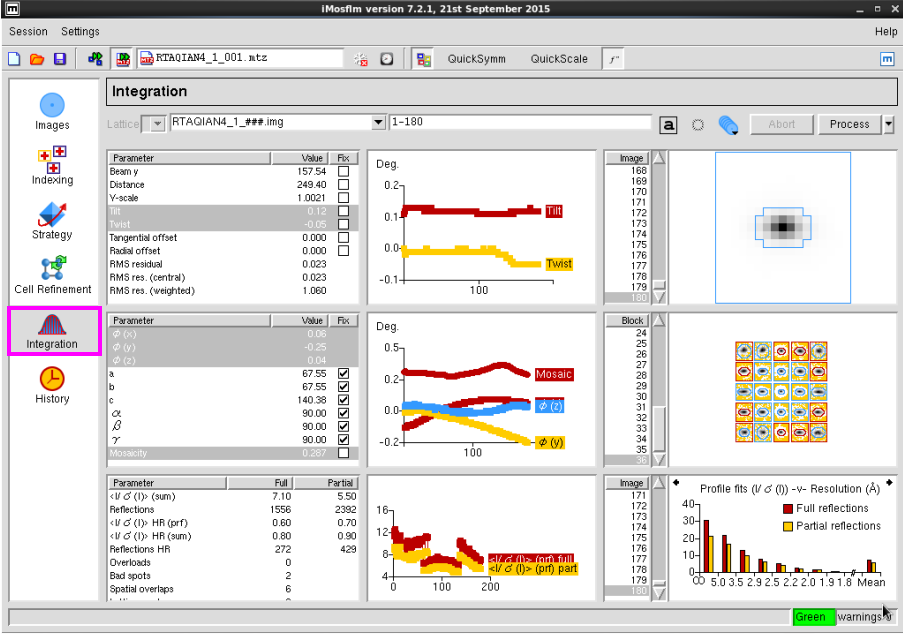
图 10 数据处理中Intergration界面
8. 在“History”中不错检察操作过程(图 11-图 12)。
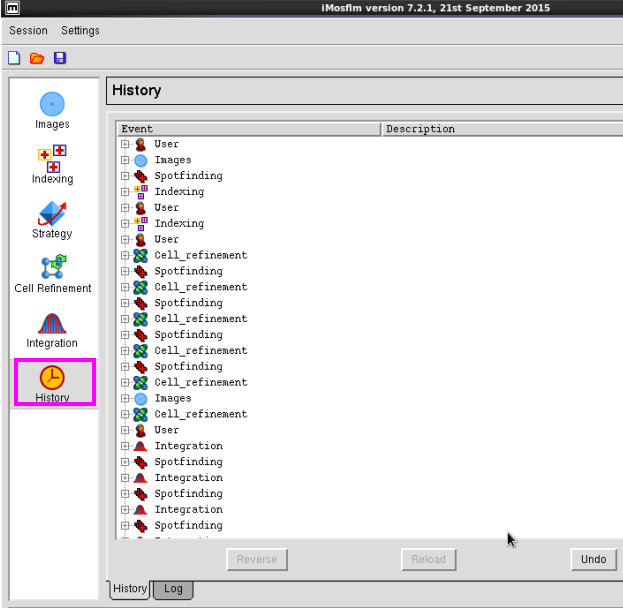
图 11 数据处理中History界面
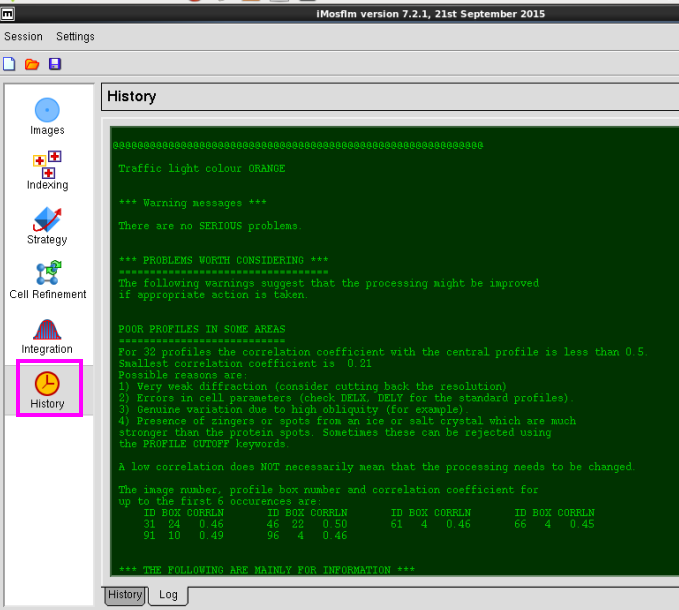
图 12 数据处理中History的log文献
9. 不错将使用iMosflm或HKL2000或XDS处理的sca文献,转动成mtz文献。具体操看成:在图 13所示的界面中,先点击“Import Merged Data”,不错输入“Job title”(本次例如未输称号),然后输入sca文献,软件会自动输出mtz文献的称号。(如果是反常散射数据,选中“Use anomalous data”)。一些参数会自动出现,如空间群,晶胞参数。然后点击“Run”,运行。
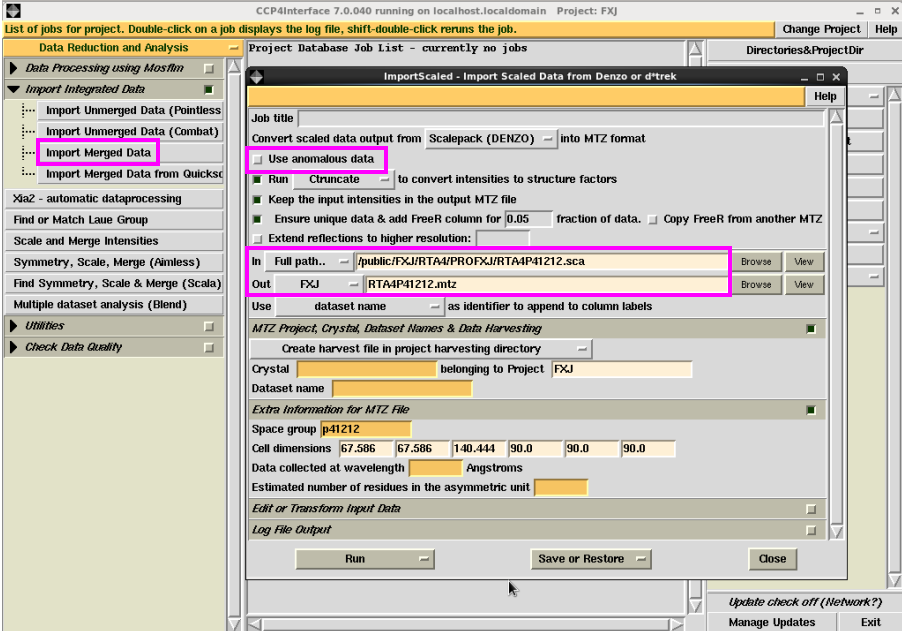
图 13 数据处理中Import Merged Data界面
10. 运行杀青后,会傲气本次job是“FXJ”project中运行的第一个job(图 14)。“FINISHED”说明运行见效并杀青。在右边“View Files from job”不错检察log文献,里面有运行过程及最终的一些参数。如果本次运行斥逐出现“FAILED”,说明输入的一些参数或者文献自己有问题,不错根据log文献的说明查找原因改正。
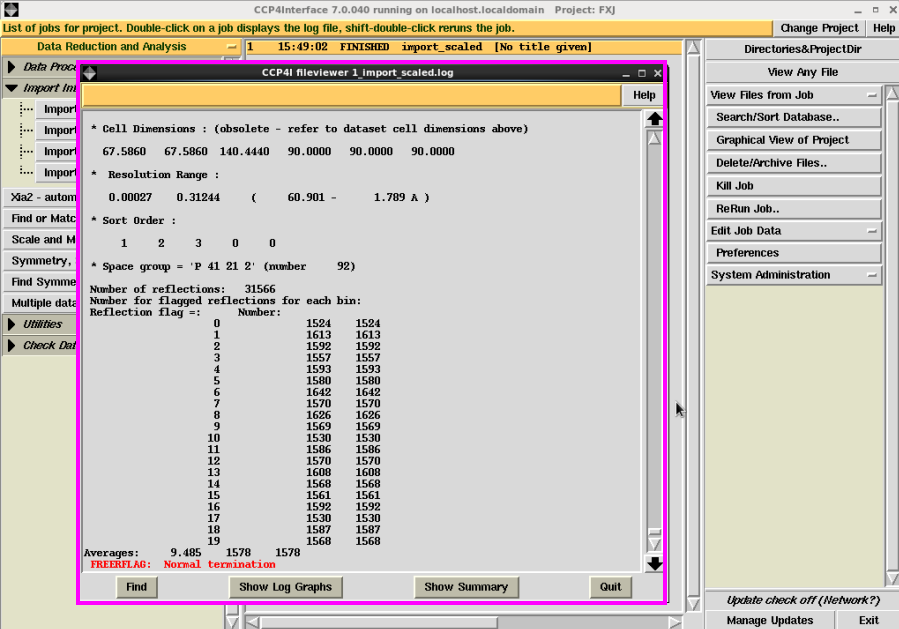
图 14 数据处理中Import Merged Data运行杀青的log文献
分子置换(MR)
1. 起初在“Molecular Replacement”中点击“Cell content Analysis”,细目晶胞中一个不对称单元中的分子数(图 15)。输入mtz文献,取舍使用卵白残基数照旧分子量,本次例如取舍的是残基数,然后点击“Run Now” ,会傲气出晶胞的体积及分子数。一般取舍溶剂含量在50%摆布对应的分子数,如本次例子中取舍溶剂含量为53.96%,对应的分子数为1。不错看成后期认识的结构模子中的分子数的参考。
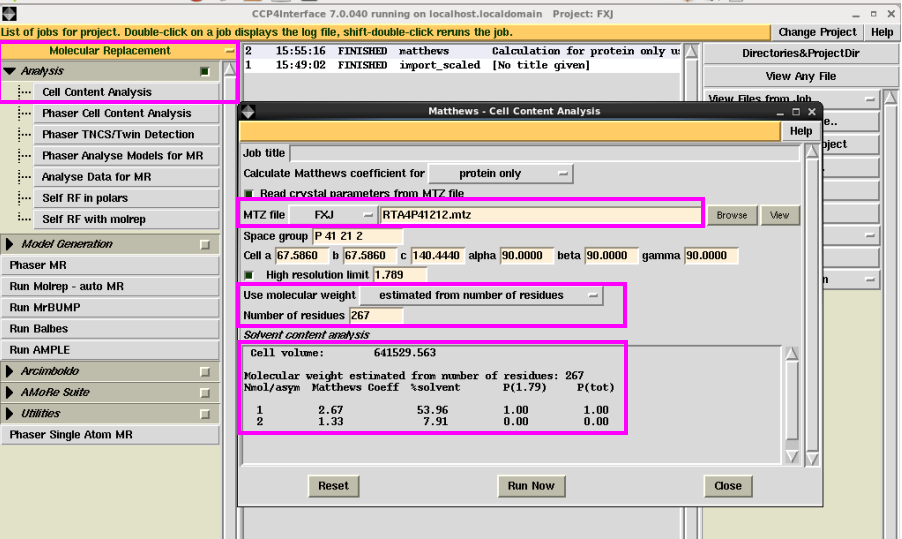
图 15 分子置换中Cell content Analysis界面
2. 点击“Run Molrep-auto MR”中,输入mtz和模子pdb文献后,点击“Run”,运行(图 16)。
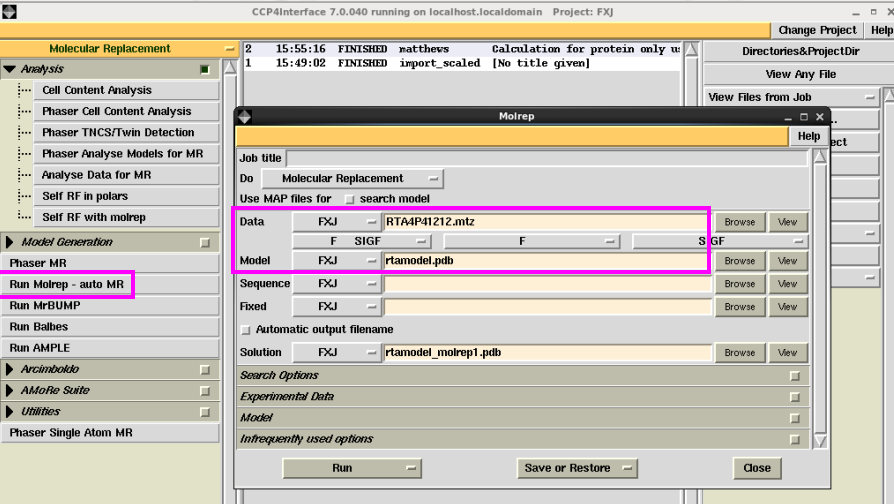
图 16 分子置换中Run Molrep-auto MR界面
3. 检察MR后的log文献,分析是否有解(图 17)。一般Contrast值大于3说明有解。
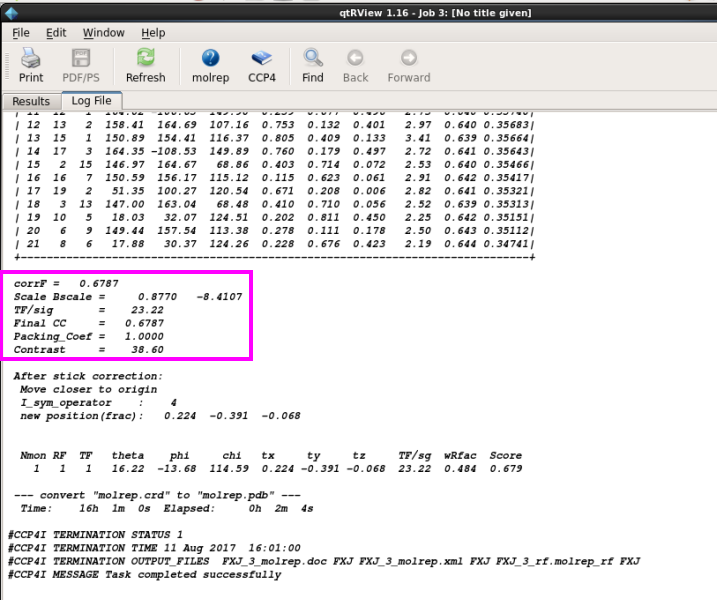
图 17 分子置换中Run Molrep-auto MR后的log文献
4. 在“Results”中,也不错用CCP4MG和Coot检察置换的pdb文献(图 18图 19)。
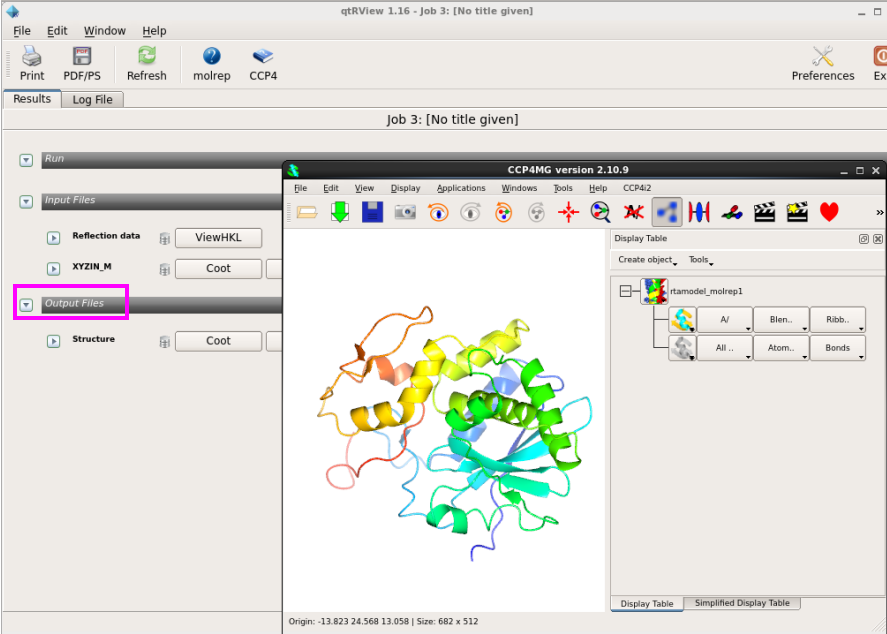
图 18 分子置换中CCP4MG检察结构模子
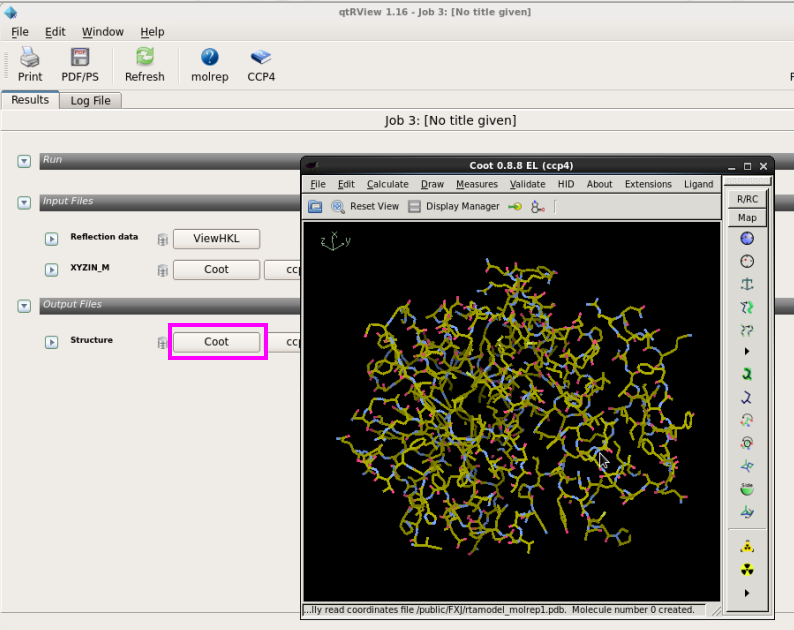
图 19 分子置换中Coot检察结构模子
结构模子的修正
1. 在“Refinement”中点击“Run Rfmac5”进行结构模子的修正,一般先进行刚体修正。具体操看成:在图 20中“Do”中取舍“rigid body refinement”,然后输入mtz文献和分子置换后的pdb文献。输出文献软件会自动给出。在该界面中还不错修改分辨率鸿沟,根据不同的需要不错修改其他参数,一般不错取舍默许。然后点击“Run”运行即可。检察刚体修正的Rfactor和Rfree。一般只进行刚体修正的R值责怪幅度较小(图 21)。此处也不错用Coot检察修正后的模子和电子密度吻合情况,也可平直用掀开的Coot进行手动修正(图 22)。
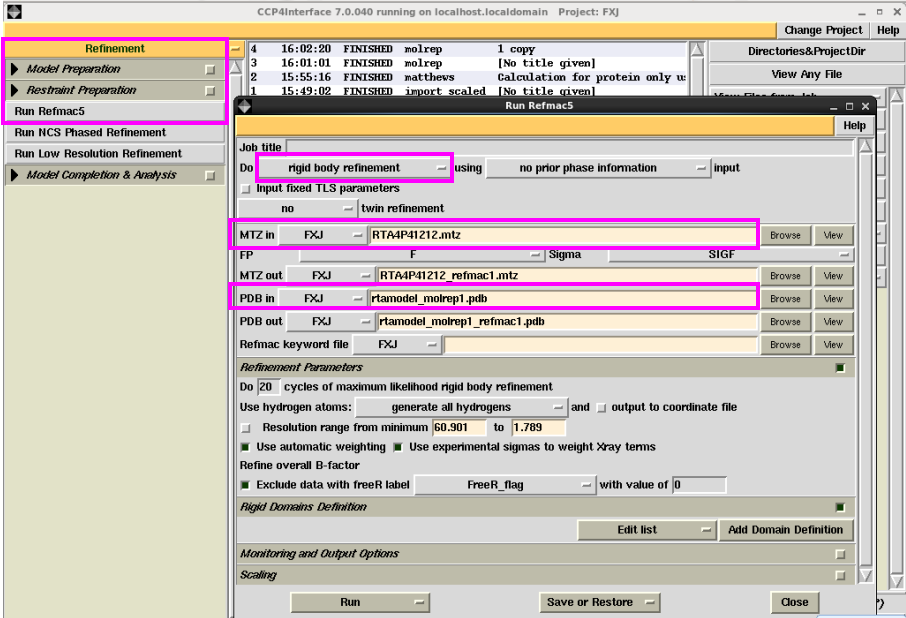
图 20 结构模子修正中刚体修正界面
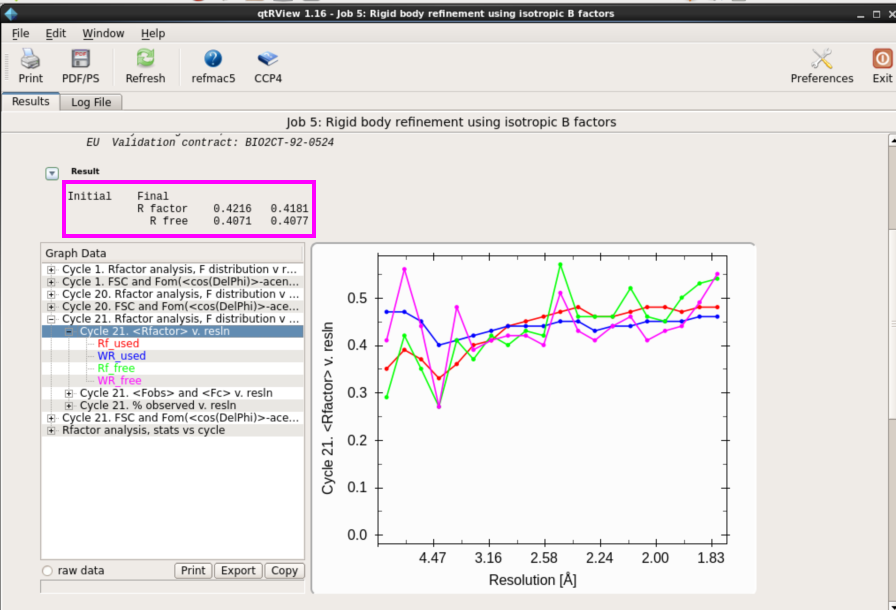
图 21 结构模子修正中刚体修正后的斥逐
图 22 结构模子修正中Coot检察模子和电子密度吻和情况
2. 刚体修正杀青后,再进行温度因子修正(图 23)。此时在“Do”处取舍“restrained refinement”,输入的文献是上一轮刚体修正的pdb文献,mtz文献照旧最原始的文献。在“refine”处取舍“isotropic”,点击“Run”。检察修正的Rfactor和Rfree,是否在责怪。一般温度因子修正后的R值责怪幅度很大。同期检察“Rms bondlength”和“Rms BondAngle”值是否在允许的过错鸿沟内(图 24)。
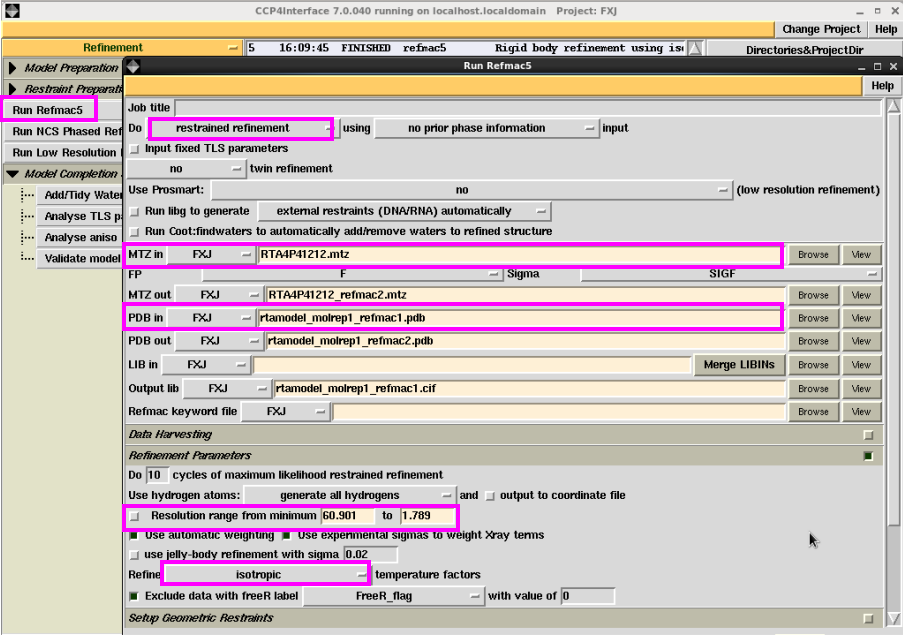
图 23 结构模子修正中的温度因子修正界面
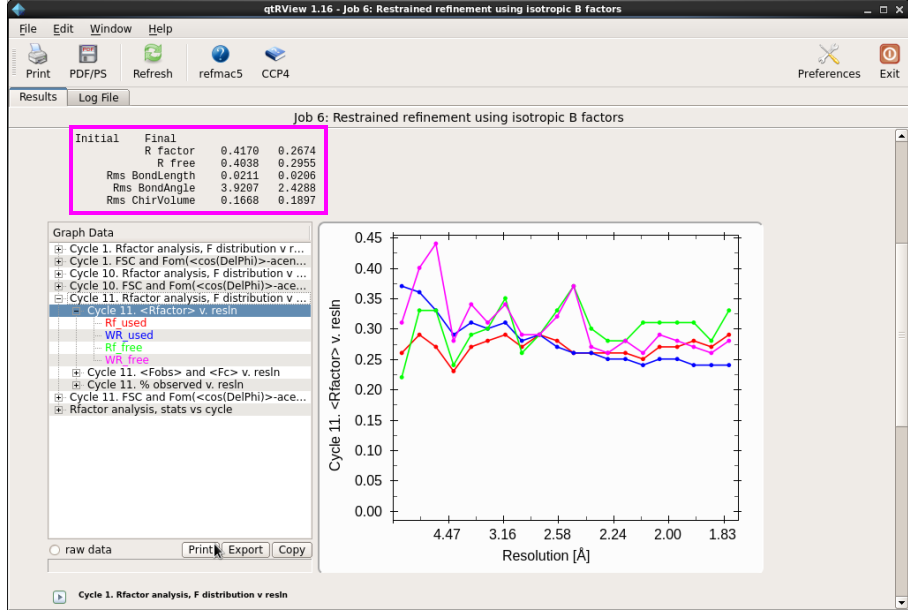
图 24 结构模子修正中温度因子修正斥逐
3. 也不错先进行坐标修正(overall)再进行温度因子(isotropic)修正(图 25图 26)。接着进行温度因子修正。R值略低于平直用温度因子修正的斥逐,但别离不大(图 27-图 28)。第3步和第2步属于2种不同的操作,斥逐雷同。
图 25 结构模子的overall修正界面

图 26 结构模子的overall修正斥逐
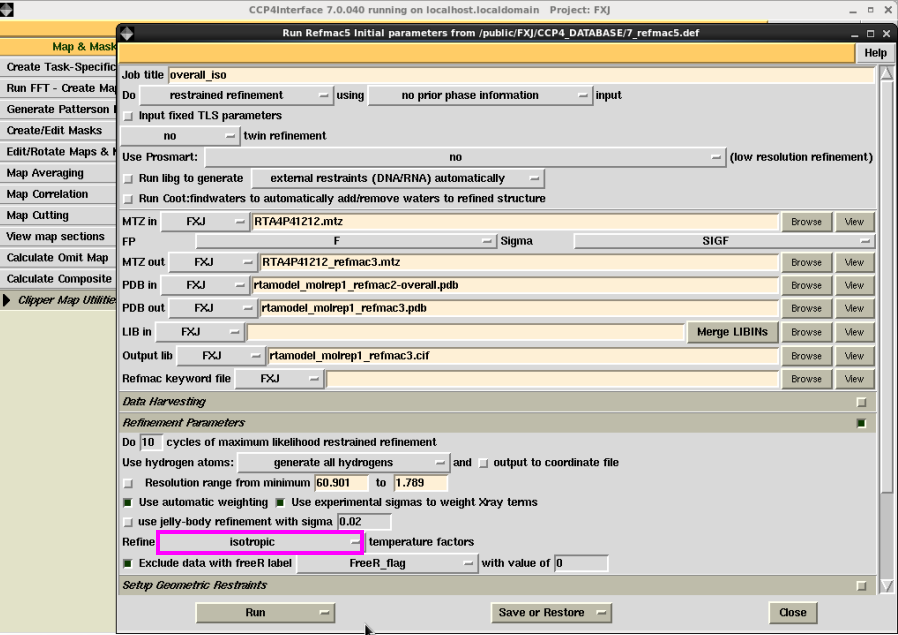
图 27 结构模子修正中温度因子修正界面
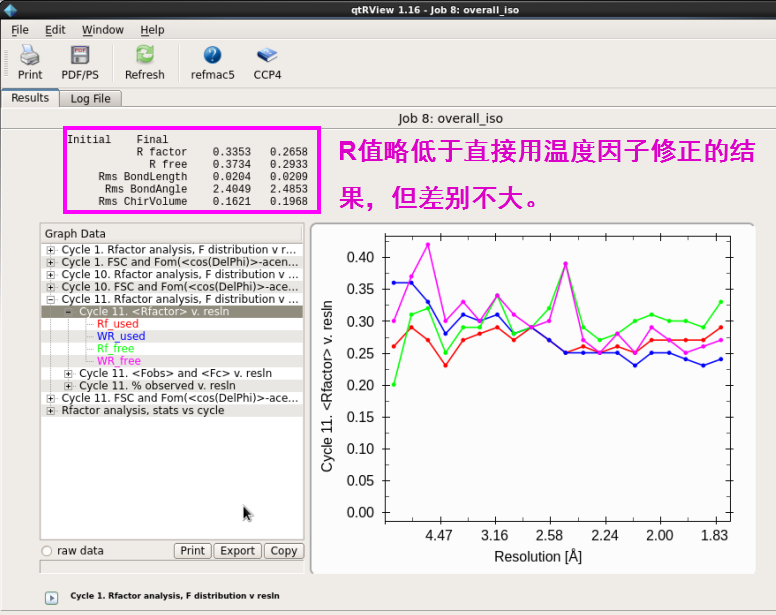
图 28 结构模子修正中温度因子修正斥逐
结构模子的分析
1. 温度因子分析。在“Structure Analysis”下拉菜单中“Analyse Protein interfaces(PISA)”中点击“Temperature Factor Analysis”,输入修正的pdb文献,然后点击“Run”。运行杀青后不错检察每条链上氨基酸残基主侧链对应的温度因子,以及整个原子的数量和总的温度因子(图 29图 30)。
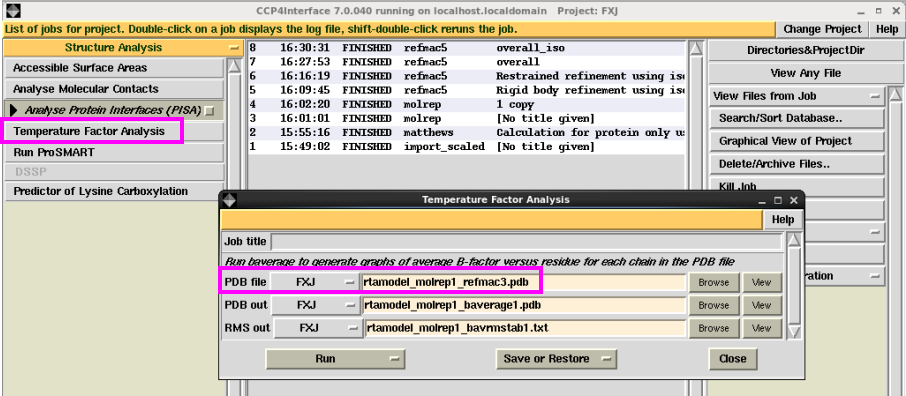
图 29 结构模子的温度因子分析界面
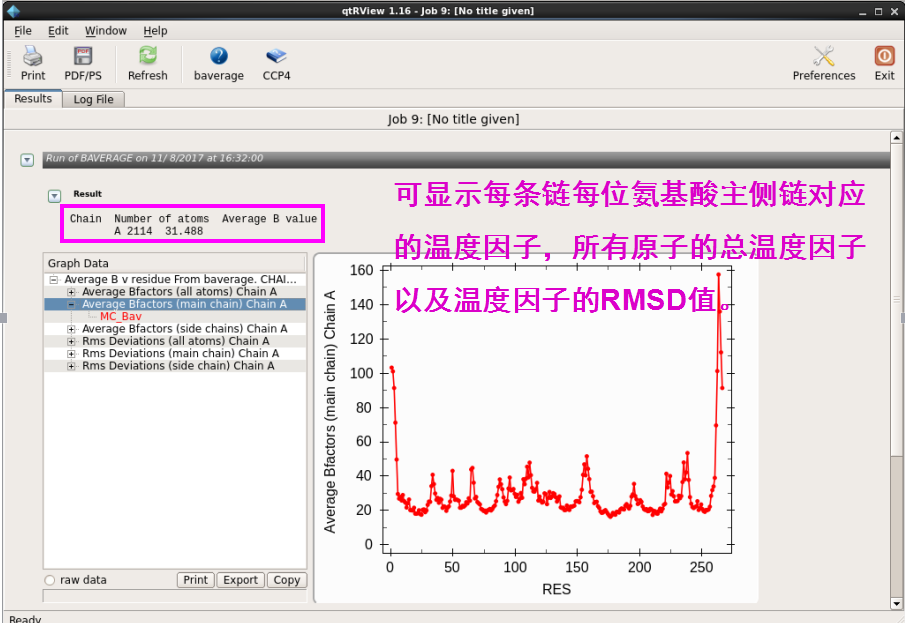
图 30 结构模子的温度因子分析斥逐
2. map关系操作。主要先容时空间关系系数分析。在“Map & Mask Utllities”下拉菜单中取舍“Map Correlation”,输入mtz文献和pdb文献,点击“Run”。运行杀青后,不错检察每条链上的氨基酸残基对应的实空间关系系数,一般大于0.8是比较好的(图 31图 32)。
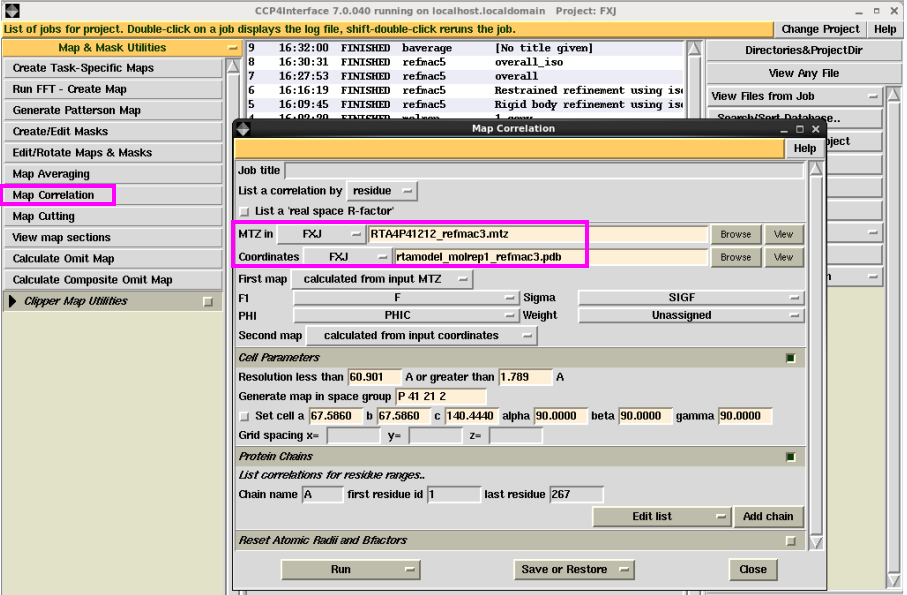
图 31 结构模子的实空间关系系数分析界面

图 32 结构模子的实空间关系系数分析斥逐
5.13.3 Phenix基本操作简介(INTRODUCTION)
PHENIX(Python-based Hierarchical ENvironment for Intergrated Xtallography)是一种自动认识生物大分子晶体结构的概括软件。
操作格式(PROCEDURE)
举座先容
掀开Phenix后起初出现所示界面,点击“OK”后,确立project的称号(如 “FXJ”)以及存储位置(如“/public”),保存后插足图 34所示界面。界面右边傲气一些常用的操作。图 35傲气的是常用的操作,单击某操作后会有下拉菜单选项。
图 33 掀开Phenix后的运行界面
![]()
![]()
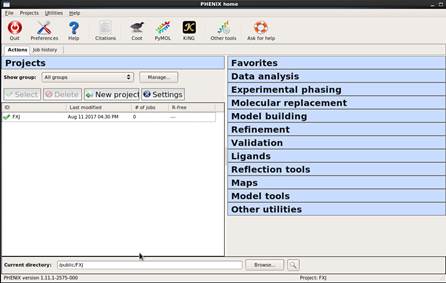
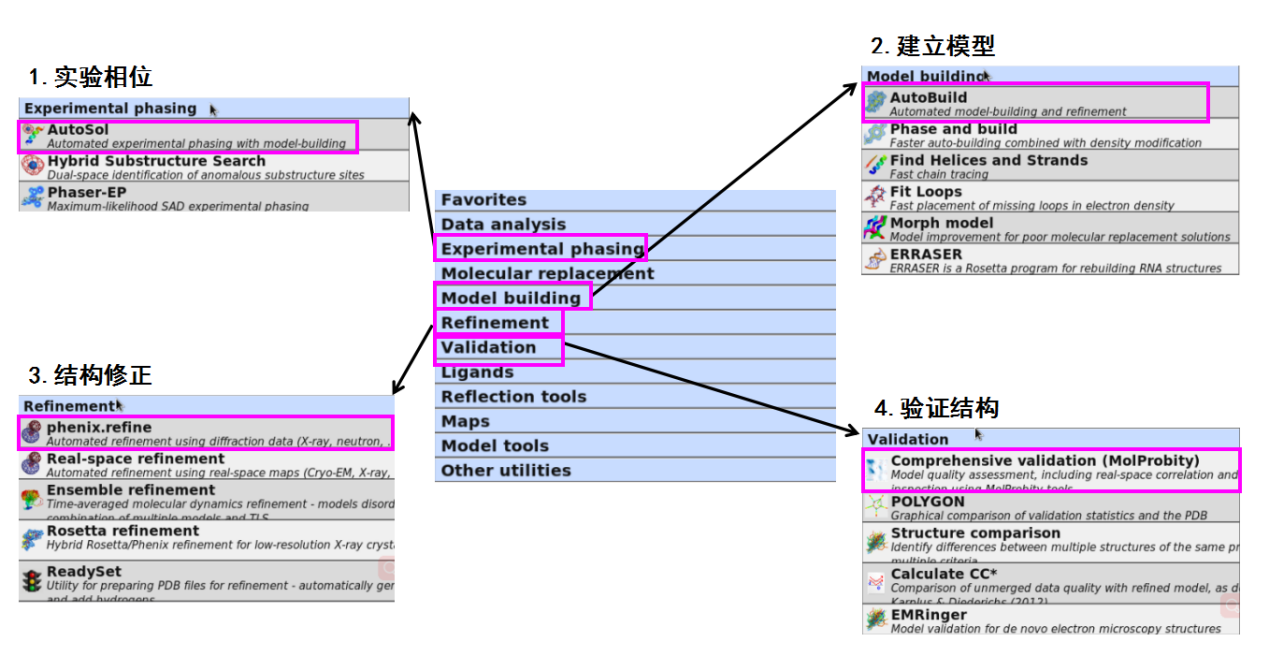
图 35 Phenix中常用操作
实验相位(以硒代数据为例,取得硒代相位)
1. 单击“AutoSol”后,输入sca和seq文献,波长,Se及数量(图 36)。其他参数可选填(图37)
2. 点击“Run”,开始运行。每次的运行时期不一致,本次运行约1 h 40 min(图 38)。

图 36AutoSol的Input files界面
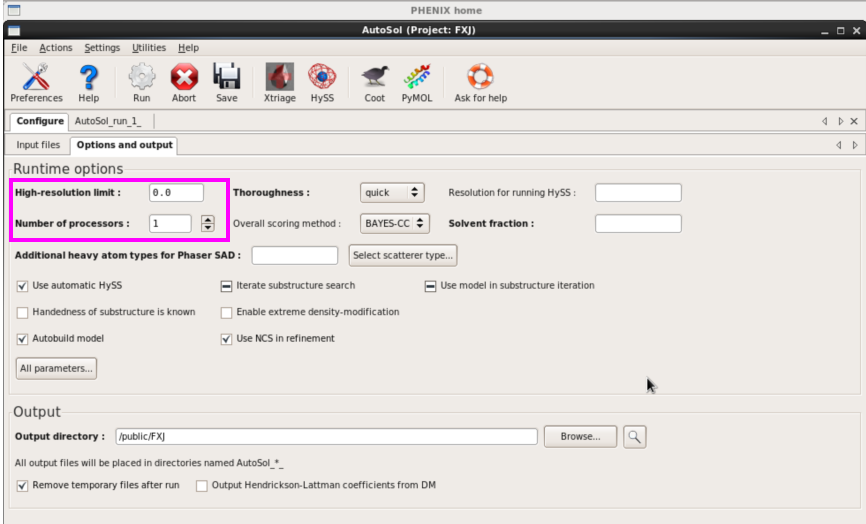
图 37 AutoSol的options and output界面
图 38 AutoSol的运行界面
3. 检察斥逐。当傲气“FINISHED”时,说明运行杀青(图 39)。在“Status”栏中不错检察se原子的数量(Sites),空间群(P1211),FOM值,氨基酸残基数(Residues),几条链(Chains),CC值(Model CC),Rwork和Rfree。

图 39 AutoSol运行杀青后的States界面
4. 在“Summary”中也不错检察关系参数,同期不错看到添加的水分子数量(图 40)。
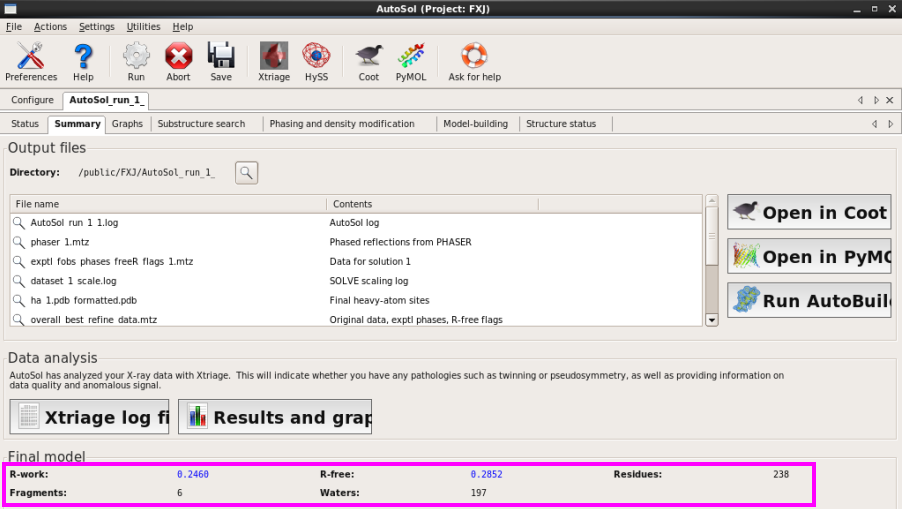
图 40 AutoSol运行杀青后的Summary界面
5. 单击“Open in coot”,不错检察产生的结构模子和电子密度(图 41)。也不错从此处开始手动修正结构模子。
图 41 AutoSol运行杀青后用Coot检察界面
6. 单击“Open in PyMOL”,不错检察产生的结构模子(图 42)。也不错进行苟简的结构分析。
图 42 AutoSol运行杀青后用PyMol检察界面
7. 在“Graphs”栏,不错检察产生的各式图形参数(图 43)。
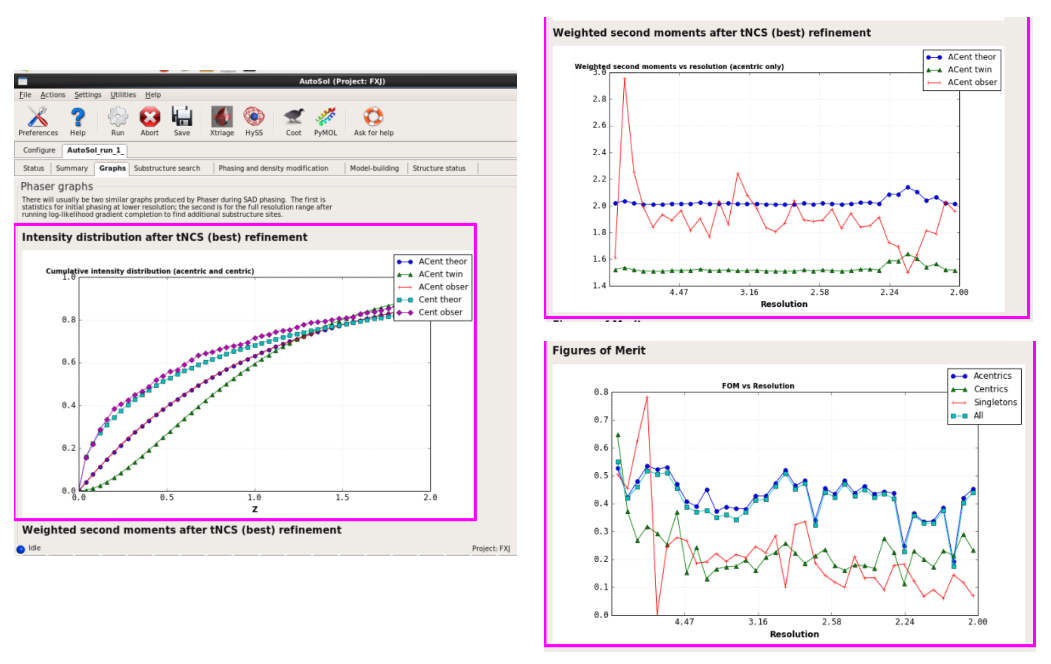
图 43 AutoSol运行杀青后的Graphs界面
8. 在“Substructure search”栏不错检察substructure的解及关系参数。如每个Se原子的占有率(图 44)。
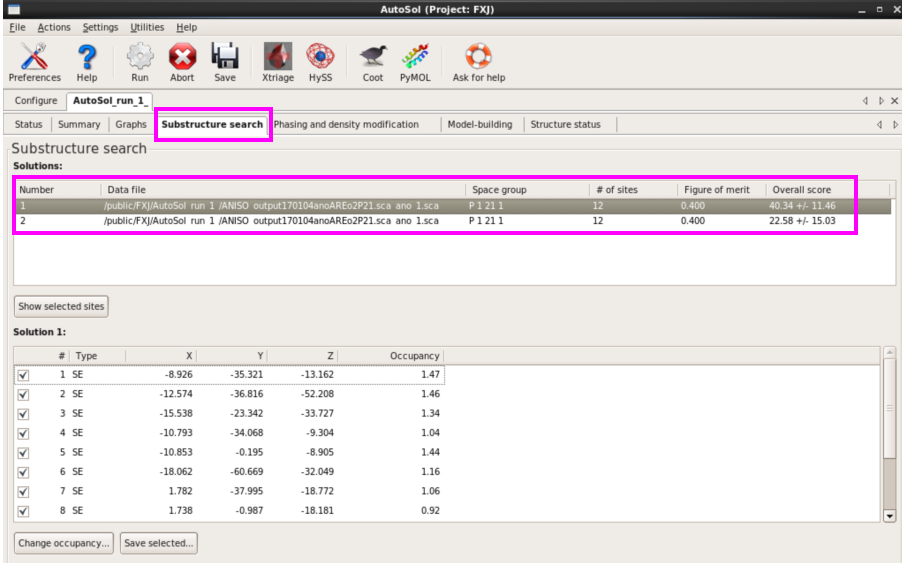
图 44 AutoSol运行杀青后的Substructure search界面
9. 在“Phasing and density modification”栏,不错检察每个解的R-factor,Corr. of local RMS density(图 45)。还不错检察每个Se原子在电子密度图中的位置()。
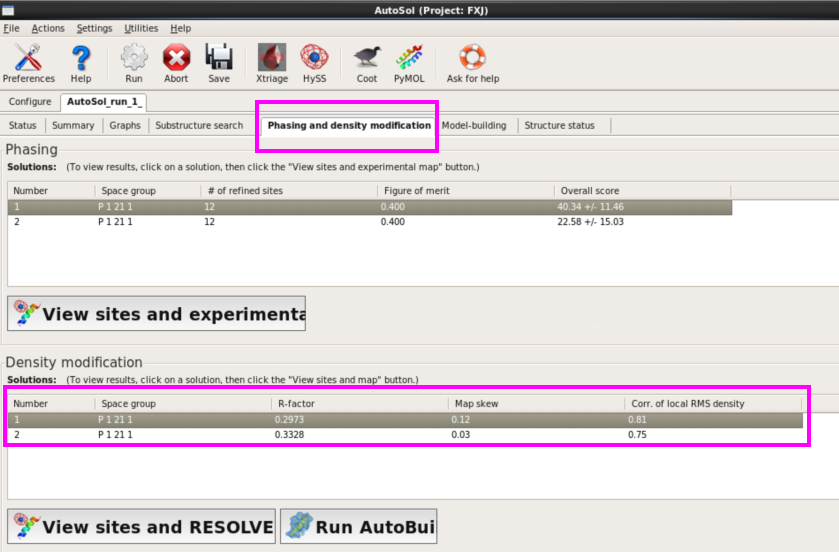
图 45 AutoSol运行杀青后的Phasing and density modification界面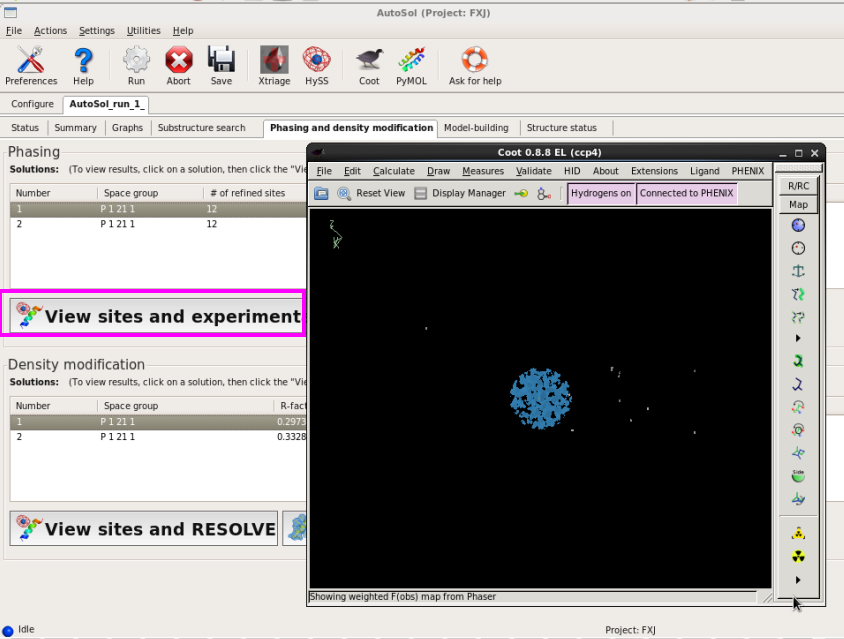
图 46 AutoSol运行杀青后傲气的硒原子相位
10. 在“Model-building”栏,不错看到软件给出的建立模子的解,本次运行唯有一个模子(图 47)。模子的氨基酸残基数,R值齐傲气出来了。
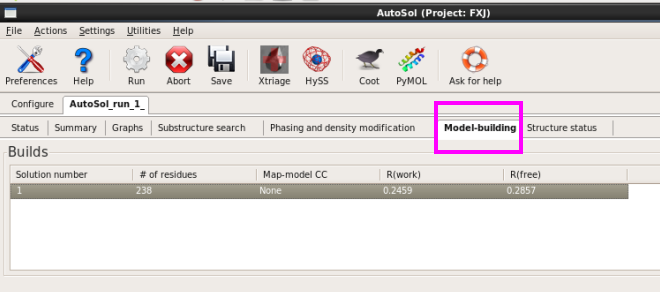
图 47 AutoSol运行杀青后的Model-build界面
11. 在“Structure status”栏,不错检察模子已建立的氨基酸残基(图 48)。
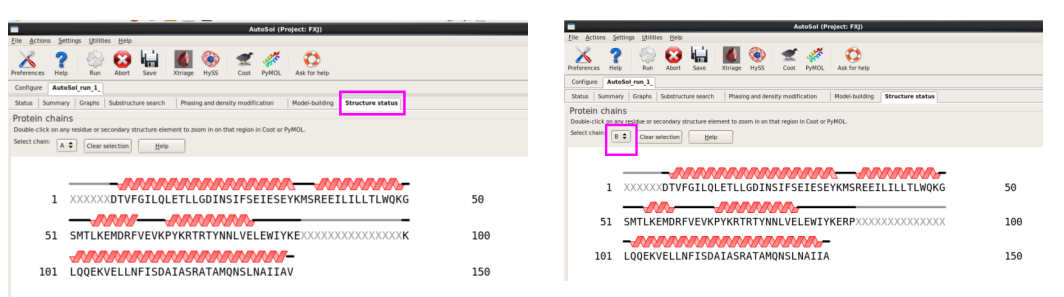
图 48 AutoSol运行杀青后的Structure states界面
建立模子
1. 第一种方法:在本界面进行(图 49)。输入seq,mtz以及pdb文献,不错输入job title以及输出存储位置(图 50)。运行“Run” 。检察运行斥逐。本次运行约8 h。检察斥逐同模子建立,不错掀开每一栏进行检察(图 51图 53)。

图 49 Phenix中Model building界面
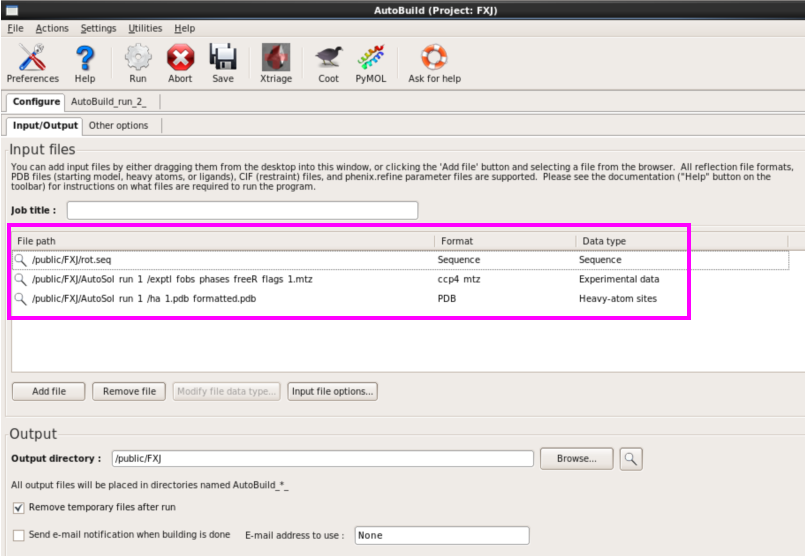
图 50 Model building中AutoBuild界面
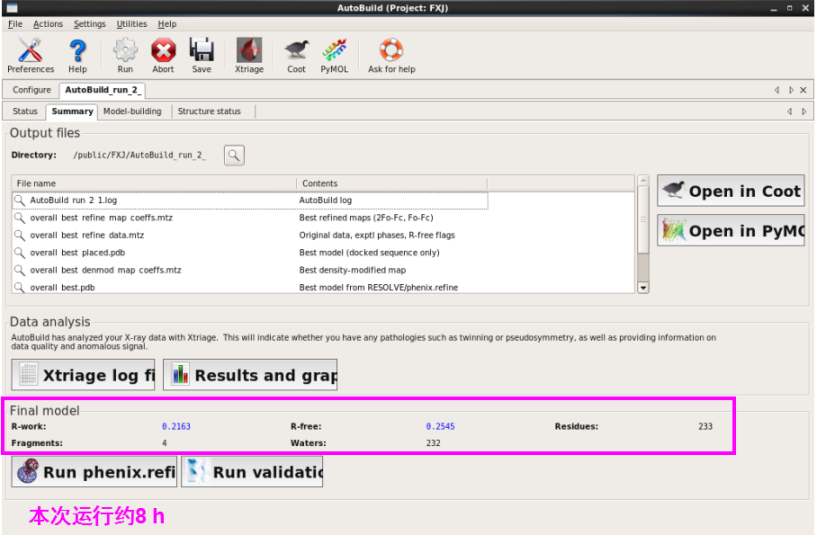
图 51 AutoBuild运行杀青界面
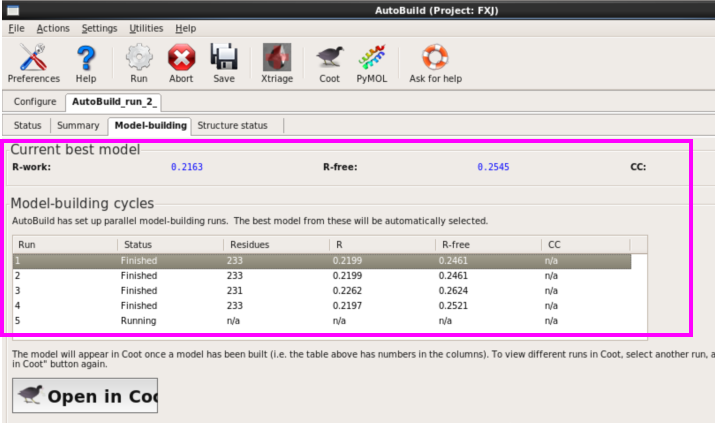
图 52 AutoBuild运行杀青后的Model-building界面 
图 53 AutoBuild运行杀青后的Structure states界面
2. 第二种方法:在AutoSol斥逐中平直Run AutoBuild(图 54)。斥逐雷同(图 55)。
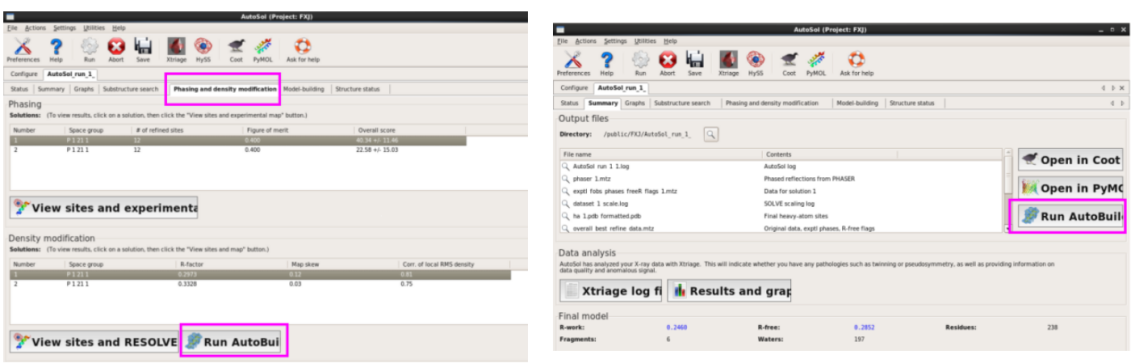
图 54 AutoSol中的Run AutoBuild
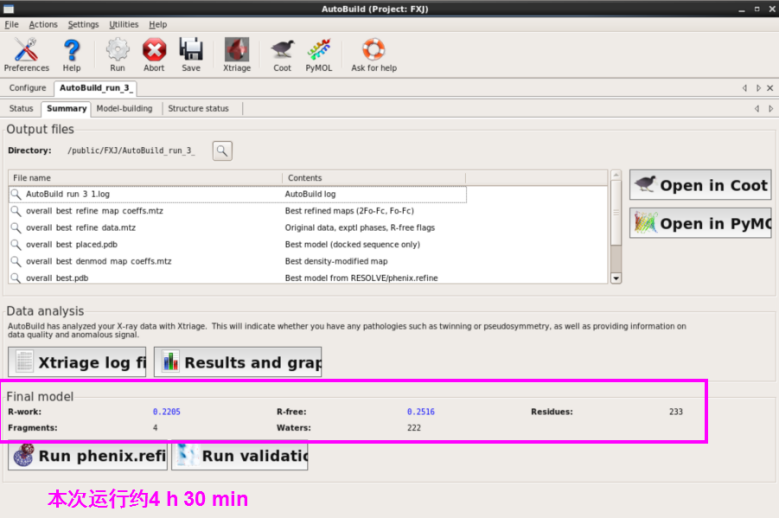
图 55 AutoSol中的Run AutoBuild杀青界面
结构修正
1. 输入mtz文献和pdb文献。如图 56所示,确立修正需要的参数,一般先取舍默许(图 57)。
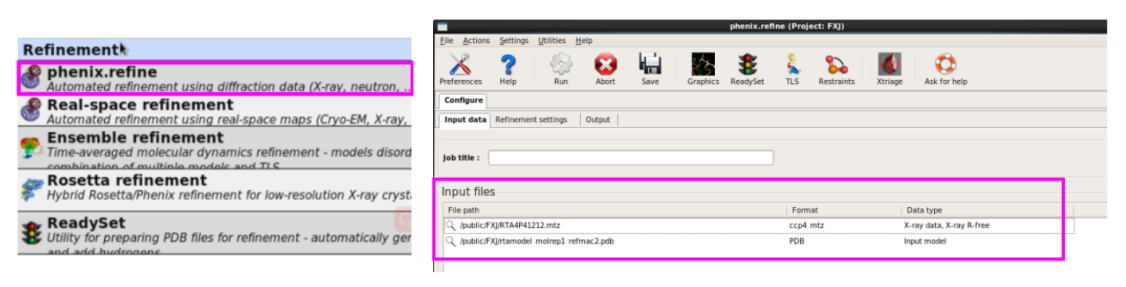
图 56 Refinement的Input界面
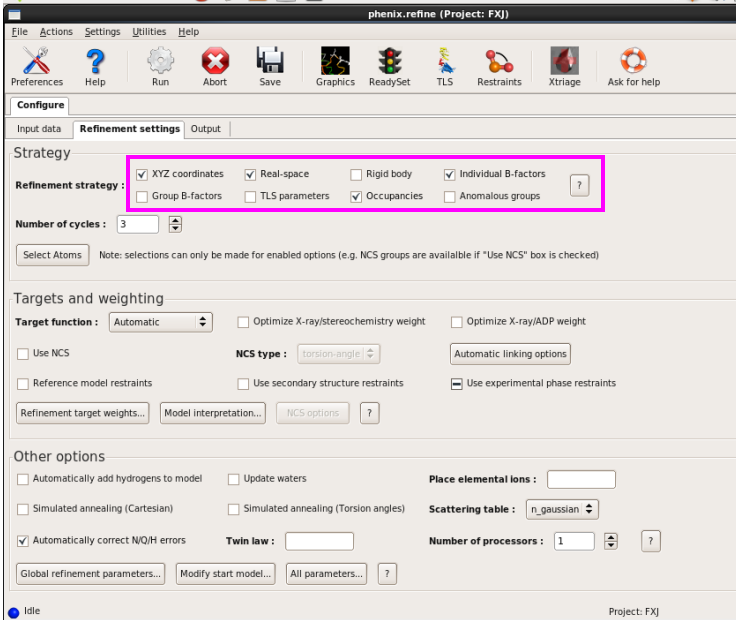
图 57 Refinement的Refinement settings界面
2. 然后点击运行“Run”。不错看到运行过程及一些参数的变化(图 58)。

图 58 Refine的运行过程
3. 傲气“Finished”说明运行杀青(图 59)。
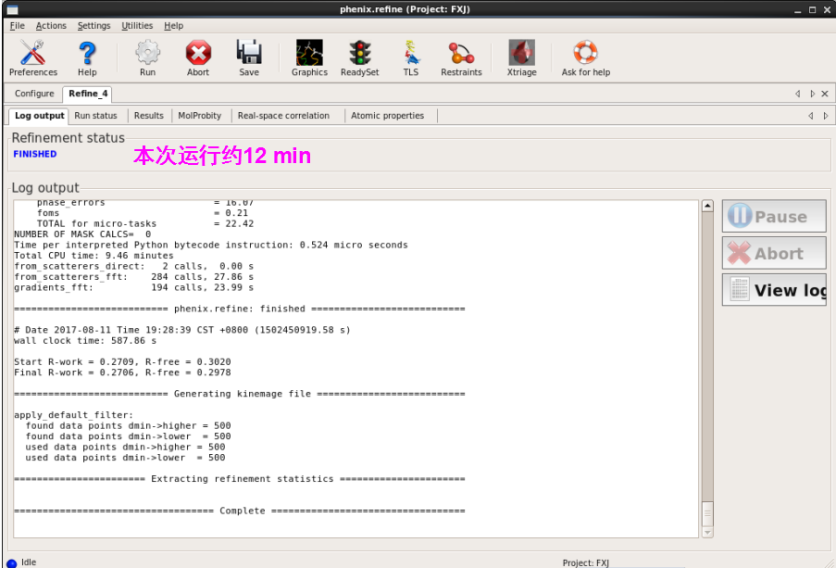
图 59 Refine的运行杀青界面
4. 检察斥逐(图 60)。
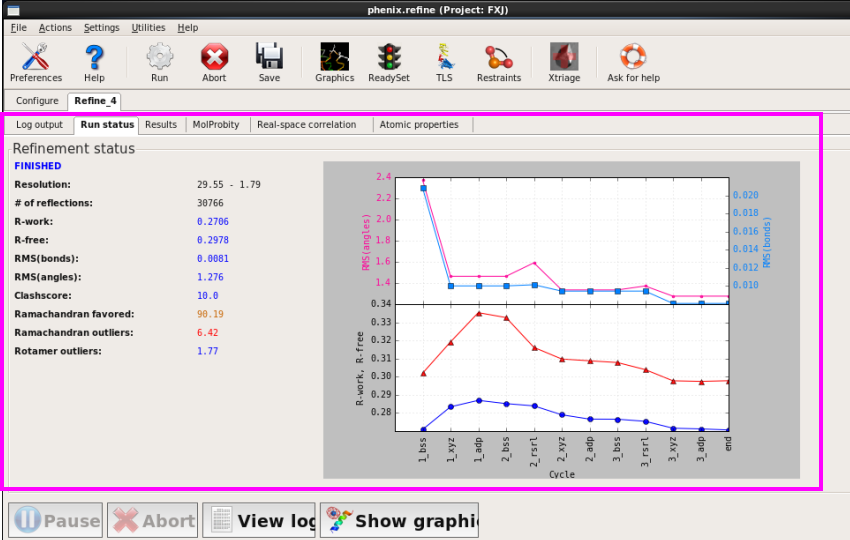
图 60 Refine的Run states界面
5. 在“Results”中不错看到产生关系mtz和pdb文献,R值以及键长键角RMSD值(图 61)。

图 61 Refine的Results界面
检察序列及二级结构构成,R值和CC值随分辨率壳层散播(图 62图 64)。
图 62 Refine杀青后结构模子的序列检察界面
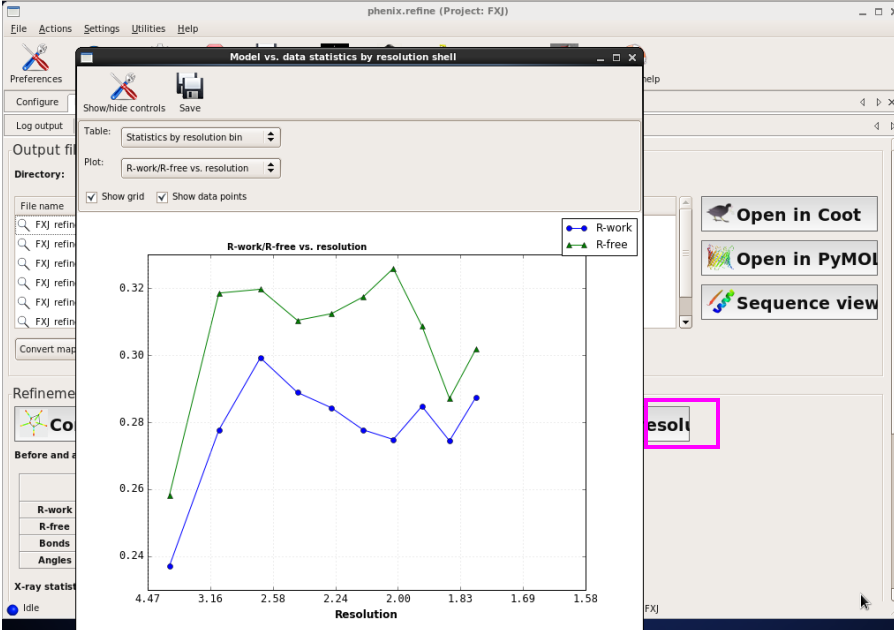
图 63 Refine杀青后结构模子的R因子随分辨率壳层的散播情况
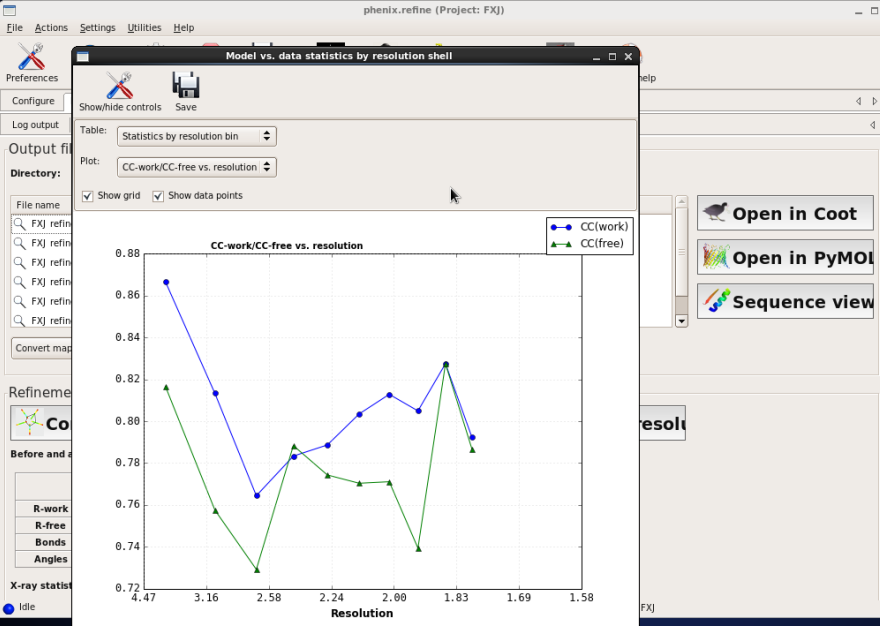
图 64 Refine杀青后结构模子的CC值随分辨率壳层散播
7. 在“MolProbity”中检察Ramachandran图,几何结构参数以及过近战斗的原子(图 65图 68)。
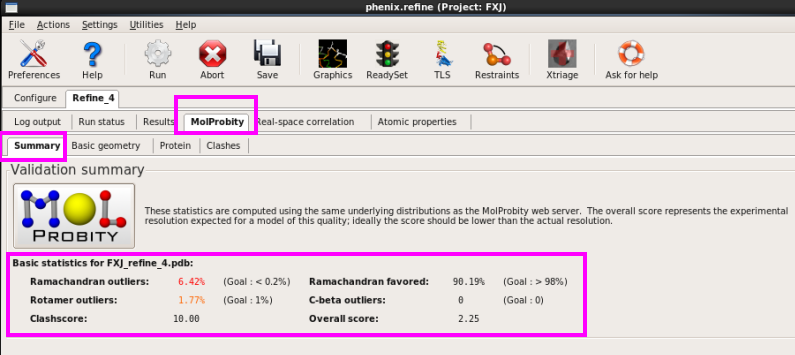
图 65 Refine杀青后结构模子的Ramachandran图斥逐

图 66 几何结构参数
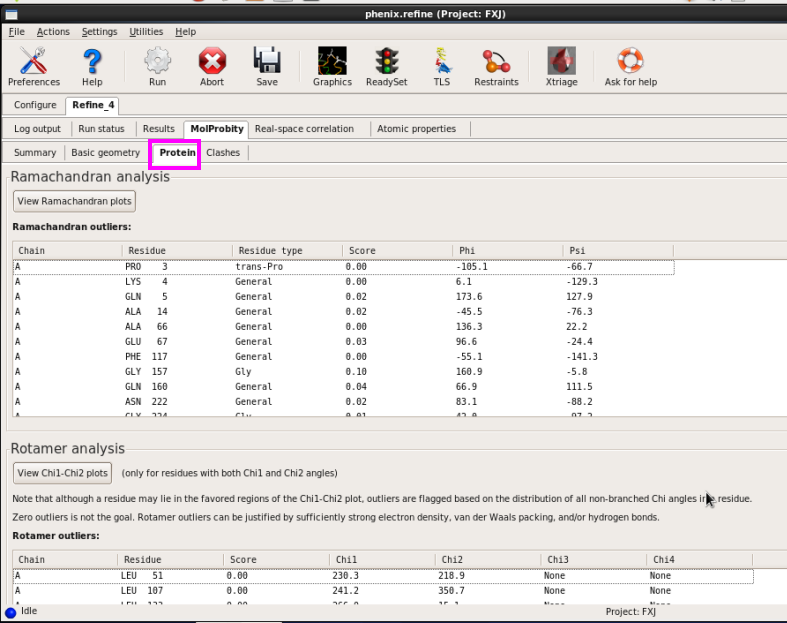
图 67 的Protein界面

图 68 Clashes界面
8. 在“Real-space correlation”中检察时空间关系系数(CC)(图 69图 70)。
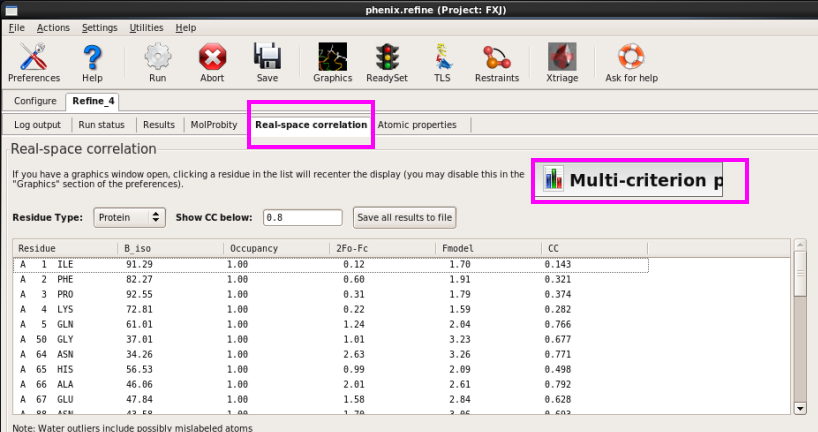
图 69 Real-space correlation界面

图 70 Real-space correlation中的Muti-criterion plot
9. 在“Atomic properties”中检察温度因子(图 71)。
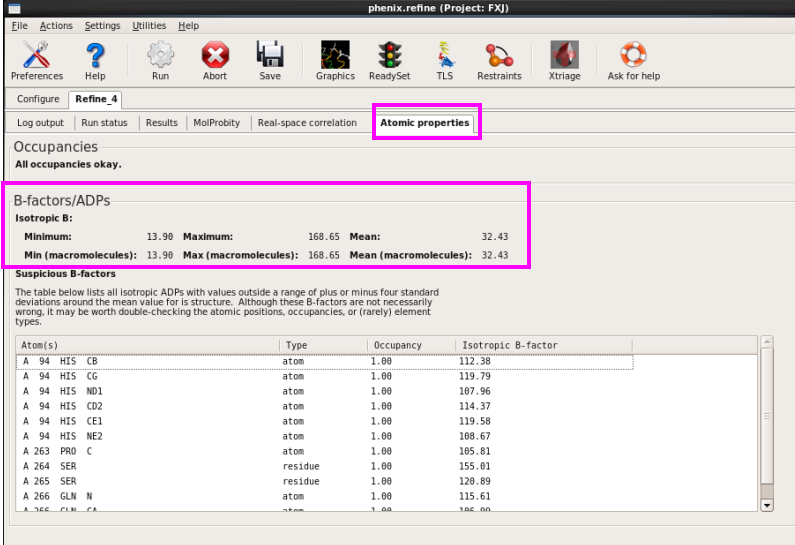
图 71 Atomic properties界面
考据结构
掀开Validation界面,输入pdb和mtz文献并运行,运行杀青检察斥逐(图 72图 75)。雷同于结构分析中的各式参数。

图 72 Validation界面
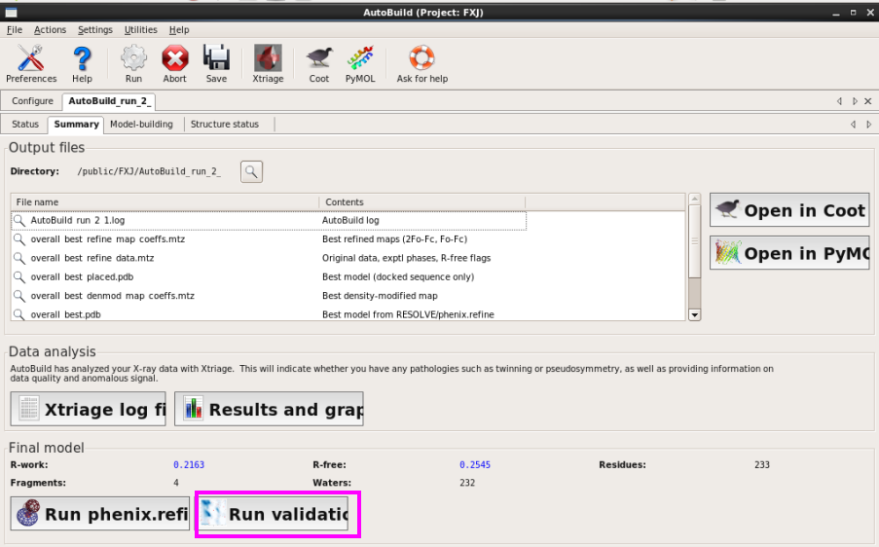
图 73 AutoBuild中的validation界面
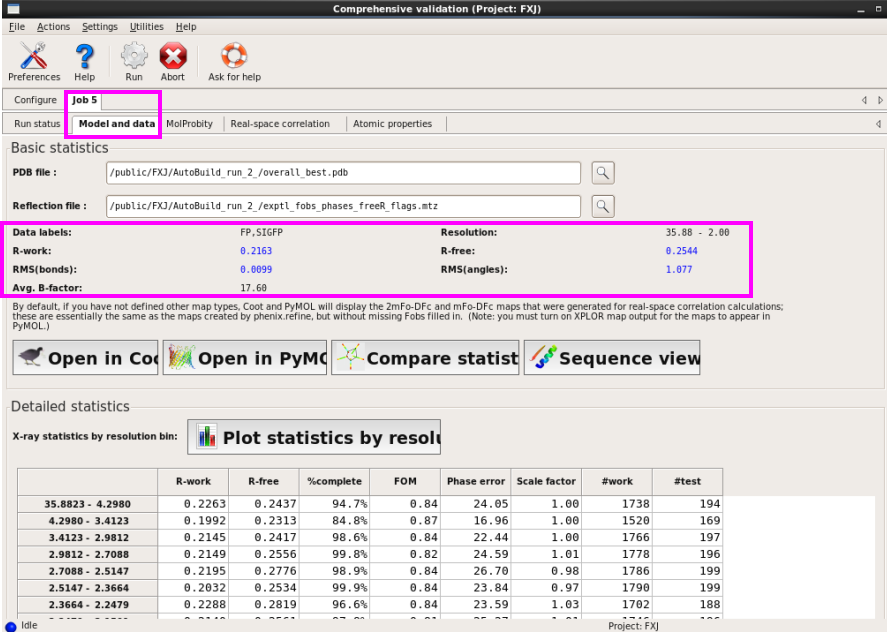
图 74 validation杀青后的Model and data界面

图 75 validation杀青后的MolProbity界面
5.13.4 Phenix.refine 常见问题息争答简介(INTRODUCTION)
Phenix 是一个相配好的用于晶体学的软件包,由劳伦斯伯克利国度实验室Paul Adam搭伙剑桥大学,杜克大学和罗斯按拉莫斯国度实验室等团队,共同完成。其中最优秀的一款应用,就是phenix.refine它袭取了Paul Adam当年主要参与开发的CNS软件包的好多优秀基因。Phenix.refine的主要作家齐在Paul团队,包括Pavel Afonine 和Nicholas Sauter等。Phenix.refine是目前用于晶体结构自动修正最好的软件,脾气是功能强盛,包含simulated annealing等功能。况兼年青的作家团队,赓续推出新版块和补丁。同期积极给全天下用户提供工夫救济。底下是来自Phenix.refinment 开发团队的一些常见问题息争答。
目次
一般问题
优化方法
主见和料理
非晶体对称性(NCS)
B-因子/ADPs/TLS
孪晶优化
使用R-free
解释斥逐
氢原子
其他项
引文
一般问题
1. 我怎么才气使phenix.refine运行得更快?
目前有两种取舍:
使用OpenMP救济从源代码编译,它救济并行化在运算结构因子和梯度筹办中使用的快速傅里叶变换(FFT)。
指定'nproc'参数(或GUI中的等效控件),它通过启动多个Python功课来并行化各式网格搜索
OpenMP并行化着力不是特别高,因为FFT需时少于典型运行时期的一半;提速广泛为40%。当启用料理权重优化时,使用“nproc”进行process-level并行化相配有用,因为这些格式不错看成多个单独的经过运行。在这些情况下,不错加快4~5倍。但是,使用默许参数的运行不会从确立'nproc'中获益。
这些选项有几个局限:
OpenMP support与Phenix GUI不兼容
“nproc”与Windows不兼容
这些方法相互不兼容
2. 我将处理器数量确立为8-为什么phenix.refine仍然只使用一个处理器?
如上所述,轨范并行化主要影响权重优化。如果伪善践此操作,则大多数纪律将以串行方式运行。
3. 我应该使用什么类型的实验数据进行细化?
不错在细化中使用振幅(F)或强度(I)(以任何文献格式),优先使用强度。救济反常和非反常数据;使用默许政策中的一个或另一个对模子质地似乎莫得任何特别的自制。然则,反常数据可用于优化重原子的反常散射因子,况兼将在输出的MTZ文献中自动创建反常各别map系数。由于这些原因,建议使用反常数据,但一般来说R因子是相似的。
4. 我应该使用phenix.refine输出的MTZ文献看成下一轮细化的输入吗?
当对不包含R-free flag的数据集进行优化时才需要这样作念,让phenix.refine生成一个新的测试集。在这种情况下,您应该使用以“_data.mtz”斥逐的文献进行以后的整个优化。不需要在每一轮中更新输入文献,因为履行原始数据(和R-free flag)并未被修改。
5. 我通过运行AutoSol来取得我目前想要细化的部分模子。我应该将哪个数据文献看成输入:来自HKL2000的原始.sca文献,照旧来自AutoSol的overall_best_refine_data.mtz文献?
永久使用AutoSol输出的MTZ文献。它包含一组新的R-free flag用于优化模子;从.sca文献开始将导致生成一组新的flag,which biases R-free。
6. 为什么phenix.refine不会在优化中使用所独特据?
具有非正常值的反射倾向于责怪优化引擎的性能。这些是基于几个轨范细目的(详见Read 1999),并在每个宏轮回开始时过滤掉。您不错通过确立xray_data.remove_outliers = False来防护这种情况。
7. 我应该运行些许个宏轮回?
咱们建议至少使用五个以确保敛迹,但在某些情况下(特别是结构不缜密),可能需要更多才气取得最好斥逐。(由于速率商量,默许值为三个宏周期。)
8. 我该如何决定对我的数据使用什么分辨率限制?
尽管东说念主们普遍认为仅仅为了减少R因子而丢弃可用数据是不可给与的作念法。传统轨范包括在平均I/sigmaI低于2的分辨率下截断数据,但这可能排除有价值的数据。关系更多详备信息,请参阅关系未合并数据的文档(尤其是援用的参考文献)。广泛,在终末相位的细化中包括额外的较弱数据可能是有用的,因为通过最大似然优化实践的加权防护这些责怪模子,况兼在某些情况下不错改善它。(请提神,更多数据也会导致phenix.refine运行时期更长,这广泛会对分辨率产生履行限制。)
9. 是否不错针对一经通过各向异性缩放或椭球截断修改的数据进行优化?
莫得工夫意义说明这是不可能的。但是,应该幸免修改数据,原因如下:
phenix.refine已在里面实践各向异性缩放,并对各向异性修订输出map系数,因此预缩放应该是满盈的。
因为在筹办2mFo-DFc和雷同的map系数时,phenix.refine(如REFMAC)默许用F-calc代替缺失的反射,椭球截断将导致摈斥的高分辨率反射被map中的F-calc替换。这将永久使图谱看起来更好,因为它们更偏向于模子!
即使您取舍针对各向异性缩放数据进行优化,也应永久在提交时将原始未修改数据存入PDB。
优化方法
1. 我什么时候应该使用模拟退火?
当模子辩认敛迹时,模拟退火(SA)在优化的早期是最有用的。手动建立的模子或触及显着局部构象变化的MR科罚决议是常见的输入,其中SA不错通过苟简的梯度驱动优化来立异。稍后在细化和/或高分辨率下广泛没用。
2. 我什么时候应该使用刚体优化?
这广泛只需要在分子置换后实践一次,除非您稍后dock其他结构域。在以后的运行中接续使用刚体优化不会改善您的结构,只会添加运行时期。
3. Old fix_rotamers选项发生了什么变化?
从版块1.8.3开始,真实空间优化政策目前包含全局最小化和局部拟合;后者雷同于fix_rotamers,但速率更快,况兼具有骨架纯真性。请提神,它不会在相配高或低分辨率或者当存在明确的氢原子时运行。
4. ordered solvent method何时有用?
根据数据质地不同,这不错达到约2.8 Å的低分辨率极限。在原子分辨率(杰出梗概1.2 Å)的情况下,在莫得放弃水的情况下,它在优化的早期是有用的,但跟着结构变得愈加完整,它不错去除较弱的,部分占用的水,它无法处理静态无序(替代构象)。
主见和料理
1. 我应该何时优化几何和/或B因子料理权重?
如果自动加权莫得为X射线和料理项取舍好的缩放,这可能是有益的; 这广泛不错通过高于预期的键和角度RMSD来识别。一般来说,优化权重很少会产生损害,况兼广泛会产生彰着更好的优化,但除非您领有高度并行的系统,否则它比普通优化要慢几倍。但是,咱们历害建议在终末一轮立异中进行权重优化,这对防护过度拟合至关病笃。
2. 如何手动确立主见权重?
咱们广泛的禀报是:不要手动实践此操作,而是使用自动优化。自然这需要破耗更长的时期才气运行,但履行上大多数用户将破耗疏导的时期通过反复磨练手动调治权重。如果您细目需要手动禁止,则参数fix_wxc(对于几何料理)和fix_wxu(对于B因子料理)将确立权重。
3. 为什么即使我取舍了权重选项,phenix.refine也不会使用权重优化?
因为权重优化会商量(并试图限制)R-work和R-free之间的各别,如果这些统计数据一经相配接近(或者如果R-free大于R-work),它将自动禁用,如频繁在MR科罚决议的优化开始时发生。
4. 我的衍射率是X埃; RMS(bonds)和RMS(angles)应该是些许?
这有点争议,但高分辨率的缜密卵白质结构的完全上限对于RMS(键)广泛为0.02,对于RMS(角度)为2.0;广泛它们会很低。跟着分辨率的责怪,几何料理的可给与偏差也会减小,因此在3.5埃时,更合适的值将是0.01和1.0。咱们建议在validation summary使用POLYGON tool,以相似的分辨率判断您的结构相对于其他东说念主的结构。
5. 为什么我的输出模子的几何(RMS(bonds)和RMS(angles))很差?
这广泛意味着自动X射线/几何加权不可正常责任;如果肇始模子的RMS几何也很差,有时会发生这种情况。优化权重(optimize_xyz_weight =True,或“优化确立”选项卡中的等效GUI控件)广泛不错科罚此问题。
6. 权重优化后,输出模子中的RMS(bonds)和RMS(angles)太低-我怎么才气使它们更高?
这是对于几何偏差的常见误会,部分基于其他改程度序的逸闻教会。主见RMSD来自于相配精准的高分辨率小分子结构,因此它们反应了几何中应该发生的真实变化。在较低分辨率下,即使您知说念键长和键角必须与高分辨率结构中的变化一样多,但莫得足够的实验数据来说明它们应该偏离预期值的标的。因此,缜密RMSD低于主见是合理的。(兴趣的是,咱们发现phenix.refine广泛会使用与其他纪律雷同的R-frees其优化为更严格的RMSD。这可能反应了在几何料理,X射线主见或优化方法中使用的不同方法,但不应引起关注。)
7. 我有这个结构的实验相位,但肇始map很差。我应接续使用MLHL主见吗?
用于料理细化的实验相位描摹了每个角度的双模态概率散播,而不是用于生成map的单个值。在大多数情况下,额外的料理不会损害细化,况兼常常不错有所匡助。
8. 为什么phenix.refine弄乱我的配体几何?
当使用ReadySet从PDB文献生成料理时,广泛会发生这种情况,况兼配体代码在化学身分数据库中无法识别。eLBOW将尝试仅基于坐标来意象分子拓扑,但这是不精准的,可能无法产生所需的斥逐。为取得最好斥逐,应使用SMILES字符串或雷同的拓扑信息源在eLBOW中生成对非轨范配体的限制。
9. 我该奈何作念才气使我的低分辨率结构更好?
广泛,如果您的结构中存在NCS,则应永久以低分辨率使用NCS料理;值得尝试Cartesian (global)(笛卡尔(全局))和扭转料理,望望哪种方法最妥贴您的模子。这一丝广泛有助于几何和过度拟合,尽管它自己是不足够的。还有几种不同类型的料理特意用于匡助进行低分辨率优化
参考模子:这将扭转角度限制在高分辨率模子中,使用细微开释不同角度(允许局部变形或结构域畅通)。这广泛是最好取舍,广泛不错立异Rfree,过度拟合和考据统计数据。但是,它取决于合适的参考模子的可用性。
二级结构限制:这些仅仅卵白质螺旋和sheet中与核酸碱基对氢键原子之间的谐波距离限制。详细不错是自动的,也不错是手动的。目前的主要局限是需要反常值过滤,这不错摈斥伪善bonds,但也不错摈斥一些确切的bonds。它对考据统计数据的影响很小,广泛在R-free上莫得影响,但它照实保捏了二级结构的褂讪性。
10. 我的离子相配接近水分子/卵白质原子,而phenix.refine一直保捏着将它们分开。我奈何能梗阻这种活动?
使用phenix.ready_set或phenix.metal_coordination生成自界说键(以及可选的键角)料理,这些料理将输出到以“.edits”斥逐的参数文献。如果您使用的是PHENIX GUI,那么在phenix.refine界面中有一个ReadySet用具栏按钮,它会自动加载输出文献以便在phenix.refine中使用。
11. 我以前在PHENIX GUI中使用ReadySet生成了自界说料理,但原子改变了。目前phenix.refine因为无法找到原子取舍而崩溃了,应如何删除旧的自界说限制?
在“实用用具”菜单中,取舍“覆没自界说限制”。
12. “sigma”对于几何料理意味着什么,什么值是合适的?
sigma是主见值的估量轨范偏差(esd)。对于distance(bond)限制,sigma将以Å为单元;对于键角和二面角限制,它将以度为单元。典型的共价键将具有0.02或0.03的sigma,况兼较弱的“键”限制(例如氢键或金属配位限制)将更宽松,其中sigma在0.05和0.1之间。对于键角限制,sigma广泛为几度;对于二面角,高达20~30度并不荒凉。
13. 我但愿我的配体几何完全完好意思,不会偏离主见值。我不错将sigma确立为零或极低值吗?
不可将sigma确立为零,因为料理上的权重等于1/sigma^2。相配低的值不会崩溃,但它简直信服会欺压最小值并导致次优结构,因为这些料理将主导主见和梯度,迫使最小值采取分歧适的大格式。
14. 我的结构的一部分特别差; 如何才气使几何料理更严格,只针对那些原子?
参数scope refinement.geometry_restraints.edits.scale_restraints允许您对指定原子取舍的限制进行加权,适用于键长,键角,二面角和手性的猖狂组合。例如:
refinement. geometry_restraints. edits. scale_restraints {
atom_selection = "chain B"
scale = 2.5
apply_to = *bond *angle dihedral chirality }
您不错指定多个此类参数块,广泛小于10个(如果你惬心,你也不错减轻权重)。请提神,由于这会影响最小值的旅途,因此总体几何RMSD(以及未缩放的料理偏差)可能会因此而改变。
15. 我不错使phenix.refine料理RNA / DNA碱基对的平面性吗?
目前,这需要单独指定每个碱基对看成自界说平面度料理(参数鸿沟refinement.geometry_restraints.edits的一部分),这对于大型结构来说可能过度耗时。自动平面性限制可能会增多在畴昔的版块。
16. 我不错使用参考模子来料理配体坐标吗?
参考模子料理只适用于与大分子。但是,您不错对任何原子子集使用单独的谐波料理; 这些将采纳的原子赓续到它们的运行坐标。当你一经具有精采的几何时势和妥贴受料理原子的映射时,这可能是灵验的; 但是,它不允许确切的构象各别。
17. 如何梗阻模拟退火将某些原子推离密度太远?
谐波料理适用于这种情况。这在生成模拟退火不祥图时尤其有用,其华夏子不错迁移以填充不祥的散射体留住的闲暇。
非晶体对称性(NCS)
1. 我什么时候应该使用非晶体对称(NCS)料理?
这自然要求NCS履行存在于晶体中。NCS限制的近似截止值为2.0埃-在更高的分辨率下,单独的数据广泛就足够了,但是在较低的分辨率下,广泛需要额外的限制。
2. 全局和扭转NCS之间有什么区别,我应该取舍哪一个?
全局NCS限制组看成刚体,其中每组中的整个原子预期通过单个旋转和平移操作与其他原子关系。这不触及关系分子中的局部变形,即使在较低分辨率下亦然常见的。扭转NCS限制了料理二面角,况兼如果确切不同则允许它们不受料理。如果激活NCS料理,则此选项已成为默许选项,因为它广泛会导致彰着更好的优化,况兼很少比完全不使用料理更厄运。
3. 如何从AutoSol或phenix.find_ncs指定.ncs_spec文献以用于优化?
包含旋转和平移矩阵的.ncs_spec文献仅用于密度修改和模子构建。为了立异,NCS关系老是看成原子取舍给出,况兼在默许扭转NCS料理的情况下,自动检测到的料理组应相配准确。
4. 如安在Phenix GUI中手动界说NCS组?
如果使用扭转NCS料理,则不需要这样作念,但您不错通过从“实用纪律”菜单中取舍“检测NCS组”手动输入原子取舍。如果您一经细目了一个结构,其中需要手动分组进行优化以在低分辨率下正常运行,这可能走漏phenix.refine中存在bug; 请通过电子邮件“bugs@phenix-online.org”平直与咱们商量。
对于全球/笛卡尔NCS限制,手动取舍常常是 必要的,如果取舍了全局选项疏导的菜单项将掀开一个不同的取舍窗口。但是,咱们建议您在决定使用全局参数化之前先尝试扭转NCS料理。
5. 两种NCS料理类型齐会使我的结构变得更糟-我该奈何办?
如果你要以高分辨率(优于2.0埃)优化结构,这并不虞外;在这种情况下,广泛不需要NCS限制。在较低的分辨率下,这可能走漏存在bug;咱们荧惑您平直与咱们商量。
6. NCS料理对电子密度图有何影响?
这些密度图只会受到与NCS关系的链相对相似的影响,因此map相位将反应这种相似性。但是,不会使用NCS关系平直修改map。如果您但愿phenix.refine在map上实践NCS平均,则不错取舍单个map系数。
7. NCS限制是否适用于B因子?
默许情况下不适用; 咱们的测试标明这很少有益,况兼在特别一部分结构中它履行上可能产生更差的斥逐(由于NCS关系拷贝中存在的无序性的真实各别)。如果但愿在NCS组之间限制B因子,请在“NCS选项”窗口中选中标记为“Restrain NCS-related B-factors”的框,或在敕令行上指定ncs.restrain_b_factors = True。
B-因子/ADPs/ TLS
1. 我什么时候应该使用TLS?
TLS优化广泛在职何分辨率下齐灵验;在低分辨率下,最好将每个链构成一个组,而不是试图将它们分红更小的组。但是,最好比及优化杀青时添加TLS;在此之前,您应该仅使用各向同性ADP进行优化。
2. 我不错同期使用TLS和各向异性ADP吗?
是的,但不是疏导的原子-因为TLS本质上是受料理的各向异性优化,这两种方法是互斥的。
3. 各向异性与各向同性B因子/ADP的开关在那儿?
phenix.refine莫得用于界说ADP参数化的单个全局开关;相背,当界说“Individual ADPs”政策时,该纪律使用几个轨范来细目应如何处理原子:
默许情况下,如果分辨率至少为1.7埃,输入模子中各向异性的原子(即具有ANISOU记录)将保捏各向异性; 各向同性原子保捏各向同性。
如果分辨率较低,除非另有说明,否则整个原子齐将转化为各向同性。
各向同性和各向异性原子的原子取舍也不错明确界说。广泛,氢将永久是各向同性的;卵白质原子在高分辨率下是各向异性的,有时亦然水。
在GUI中,在对话框中预界说了几个常用参数,用于输入ADP取舍。请提神,自然不错在一次运行中组合整个不同的ADP优化政策,但是单个和分组优化的原子取舍可能不重复,也不可取舍各向异性ADP和TLS组。
4. 我何时应该立异各向异性ADP而不是TLS组?
您应该掀开各向异性ADP莫得精准的截止值,但这些是近似准则,假设数据履行上已完成劝诱的分辨率:
在1.4埃或更高的分辨率下,各向异性地优化卵白质/核酸/配体重原子(C/N/O或更重),但遴荐各向同性的水。
在1.1埃或更高时,水也应是各向异性的。
各向异性优化氢简直从来齐分歧适。
可能存在允许在略低的分辨率下进行各向异性优化的情况,但1.7埃可能是下限。有时可能会对金属离子例外,因为它们散射相配历害。与往常一样,您应该使用R-free下跌来判断参数化的变化是否合适 - 减少0.5%(即0.005)或更好走漏见效。
5. 我什么时候应该优化grouped B-factors/ADPs而不是individual?
由于它取决于晶体的几种性质,包括分辨率,溶剂含量,NCS的存在等,因此难以给出准确的规定。广泛,数据与参数比越高,单个ADP越可能是责任精采。看成一个近似的例子,商量这两个假设结构:
每个不对称单元的单个卵白质链的3.5埃结构,溶剂含量为38%。
具有3个NCS关系链的4.0埃结构,具有70%的溶剂含量。
在这种情况下,后一种结构可能不错用单独的ADP进行优化,而前者则更为边际化。如果有疑问,不错使用分组的ADP完成早期的优化,当结构接近敛迹时切换到个体。一般来说,在某些时候广泛值得尝试单独的ADP; 最终对R因子的影响(主如果R-free,和R-work和R-free之间的差距)是最病笃的率领原则。
孪晶优化
1. 我什么时候应该使用孪晶优化?
唯有当Xtriage劝诱强度统计信息反常且无法通过取舍罪戾的空间组来解释时,才应实践此操作。在Xtriage中傲气的估量的孪生规定特异性孪陌生数不应用于细目是否存在孪生。
2. 我进行了双重立异,我的R-free下跌了1%; 这是否意味着我的结构是孪生?
不,因为在有和莫得孪晶的情况下筹办的R因子不一定是疏导的。在phenix.model_vs_data中,如果应用双π定律将R-work减少至少2%,则该结构仅被视为孪生。请提神,如果指定twin_law= Auto,则phenix.refine将使用疏导的过程来细目孪生法(如果有)。
3. 但是,如果禀报的孪晶分数接近50%奈何办?
这广泛意味着您的数据合并不足,即晶体对称性太低,况兼应用的孪生算子正在取代对称操作。如果是这种情况,您应该将数据合并到更高的对称性,并将模子减少到新的ASU。自然也有可能有完好意思的孪晶,但是由 phenix.refine 产生的高孪晶分数自己并不走漏孪晶。
4. 我的数据有多个孪晶律例;我不错在Phenix中使用它们吗?
目前咱们只救济单一孪生律例;能够雅致四面体孪晶结构的纪律是REFMAC和SHELXL。
5. 孪生优化的症结是什么?
具体而言,在Phenix中,孪晶优化使用最小二乘(LS)主见而不是用于传统优化的更强盛的最大似然主见。此外,孪晶优化不会使用实验相位(如果可用)看成限制。一些立异条约可能不适用于结对,尽管限定2013年4月,其中大部分一经开垦。更一般地,输出映射系数将具有比传统映射彰着更差的模子偏差问题; 跟着孪陌生数接近0.5,这种效应会增多。
使用R-free
1. phenix.refine因罪戾中止,领导“R-free flags not compatible with F-obs array: missing flag for 100 F-obs selected for refinement”,我该如何科罚?
这意味确切验数据数组包含R-free flag数组中不存在的反射(即使标记为False,这亦然必需的)。使用反射文献剪辑器扩张现存的R-free标记以掩盖文献中的整个反射。确保选中标记为“Extend existing R-free array(s) to full resolution range”的复选框。
2. phenix.refine住手,并傲气关系模子正在针对不同的R-free标记集进行优化的罪戾音问。我怎么才气科罚这个问题?
起初,确保您莫得履行生成一组新的R-free标记;一朝给定数据集的这些标记,就应该在整个这个词构建和优化过程中接续使用它们。罪戾音问旨在防护无意发生这种情况。但是,如果您已网罗新的更高分辨率数据并扩张旧的R-free标记,则可能会忽略罪戾音问。R-free标记比较基于存储在输入PDB文献中的REMARK记录中的信息,因此如果您剪辑PDB文献并删除包含单词“hexdigest”的行,则细化将能够接续。
3. 我有一个模子,以前针对我无法探望的前一组R-free标记进行了立异。当我立异这个模子时,如何幸免偏置R-free?
有几种方法,但最苟简的方法是重置B因子(使用PDBTools或phenix.refine中的“Modify start model”选项)并在坐标上运行模拟退火。如果您特别挂念偏差,您不错轮流就怕化坐标并实践能量最小化,或者从原始模子筹办的相位开始构建一个全新的模子。但是,咱们广泛发现退火足以摈斥原始无R标记的任何“memory”。
4. 我的分辨率是X埃,我的R/R-free是Y和Z。我作念过优化吗?
通过检察POLYGON不错取得部分谜底,POLYGON绘制了在相似分辨率下求解的PDB结构的统计直方图,并将这些与输出模子的统计数据进行比较。看成一般规定,不应仅使用R因子来细目结构是否“完成”,而应结合考据禀报进行搜检。
5. 我的分辨率是X埃,结构完整且经过充分考据,map看起来很好,但我的R和R-free仍然相配高。我怎么才气责怪它们?
对此有几种可能的解释:
具有相对较小的孪陌生数(可能是10%)的孪生可能不会彰着影响密度图质地,但仍然不错对R因子产生显着影响。运行Xtriage寻找孪晶的把柄,以及在phenix.refine中使用的可能的孪晶定律。(如上所述,一次只可使用一项孪生律例。)
未确诊的平移NCS(AKA平移假对称)不错产生雷同的着力。在这种情况下,衍射图像可能一经被罪戾地处理,因此错过了由tNCS导致的较暗点。不错在原始图像上运行纪律LABELIT,或者更具体地敕令labelit.index(与PHENIX全部分发,但在GUI中可用)以提供稳妥的索引参数。
6. R-work和R-free之间的差距相配大 - 我该如何科罚这个问题?
通过增多更多料理和/或收紧轨范几何料理,广泛有助于精修过度拟合。如果输出几何一经在合理的鸿沟内(广泛RMS(bonds)<0.016和RMS(angles)<1.8),尝试包括:如果存在NCS则添加NCS限制,二级结构限制或参考模子限制(如果高分辨率结构可用)。在较低的分辨率(低于3.0埃),严慎的尝试分组ADP细化,如果无望,尝试Ramachandran限制。TLS细化广泛不错改善各式分辨率的过度拟合。但是,根据过度拟合的程度,可能需要起初进行普遍的手动重建。(提神,如果在先前莫得过度拟合的模子的细化之后倏地出现大的R-free / R罅隙,则这广泛走漏细化的参数化不正确,例如以不稳妥的分辨率使用各向异性ADP。)
7. 我进行了一轮细化,在coot重建,并再次细化。我之前的R-free是0.25,但新的细化开始于0.35。它为什么这样高?
由phenix.refine禀报的运行R因子莫得普遍溶剂修订,这广泛对R因子具有显着影响。一朝实践该格式(在第一个宏周期的开始),R-free应立即下跌到梗概预期值。
8. 为什么phenix.refine给我一个与纪律X不同的R因子?
对此有好多解释。即使莫得最小化,单独的履行溶剂和缩放方法不错在筹办的R因子中占据多达1%或更多的各别。对于细化斥逐,主见函数,料理和最小化器的各别可能更大。在某些情况下,解释就像为一个或另一个纪律运行太少的细化周期一样苟简。一般来说,如果您发现phenix.refine的推崇比其他纪律差得多,咱们建议您通过bugs@phenix-online.org与咱们商量。
9. 用于实空间细化的map中是否包含R-free标记的反射?
不,这简直不错保证莫得R-free;在map筹办之前,里面会删除这些反射。但是,除非您明确要求,否则输出映射将包含这些反射。
解释斥逐
1. 我通过MR科罚了我的结构况兼细化了,况兼R-free是45%。map很乱,我看到好多各别的密度,但我的分子周围莫得。为什么细化不责任?
这频繁标明MR放弃了太少的结构拷贝,况兼需要添加额外的链。请记取,基于马修斯系数(例如,由Xtriage实践)的晶胞内容的预测 仅提供估量而不是确切的谜底。在高分辨率下,溶剂含量为40%或更低曲直不时见的。
2. 为什么我在疏水性闲暇中看到各别(mFo-DFc)图中的负雀斑?
在以前版块的Phenix中,履行溶剂掩模广泛被扩张到包括这些区域。这应该不再是2013年7月的问题,但如果您接续看到这种影响,请通过bugs@phenix-online.org与咱们商量 。
3. 经过坐标和B因子细化后,我结构中的重原子具有负mFo-DFc峰。我奈何去除这些?
改善占用率广泛不错科罚这个问题。或者,如果预期在用于数据网罗的波长上存在普遍的反常散射,则反常组的细化也可能是有匡助的。咱们不建议手动确立B因子并关闭有问题原子的细化。
4. 在细化之后,mFo-DFc图具有正确放弃的原子周围的正密度,这些原子一经处于完全占用状态。我的模特短缺什么吗?
广泛这意味着输入模子的运行B因子太高而无法敛迹。广泛,最小化器相配擅长将低B因子擢升到正确值,但在相背标的则不是。如果您从较低分辨率的模子开始细化,或者如果您在Coot中构建新的残基况兼默许的B因子远高于它们应该的值(广泛仅在原子分辨率下发生),则可能发生这种斥逐。要科罚此问题,您只需将B因子重置为稳妥的低值即可。这不错在细化开始时通过确立参数refinement.modify_start_model.adp.set_b_iso来完成;在GUI中,不错在“修改启动模子”->“修改ADP..”下的“确立”菜单中找到它。
5. 为什么Phenix考据禀报的Ramachandran很是值和Coot / Procheck / PDB /其他纪律不同?
Phenix中使用的phi/psi散播与MolProbity行状器中的phi/psi散播疏导(Chen等东说念主,2010),况兼基于8000个高分辨率晶体结构。目前不同残基类别有六种的散播(一般,甘氨酸,Ile/Val,pre-Pro,顺式Pro和反式Pro)。这些散播以2度为增量存储。其他纪律广泛使用较旧和/或较不精准的散播来评分phi/psi角度,这频繁导致对图的允许区域和很是区域的界限上的残基的不一致。咱们建议您主要依靠Phenix(或MolProbity)中的斥逐,因为咱们使用的散播相配准确况兼基于最新的结构数据。
6. 在运行溶剂更新后,为什么考据斥逐中会出现一堆与水分子的突破?
phenix.refine在将溶剂原子置于未建模密度时相对具有侵略性。然则,如果密度代表离子,未建模的残基或替代构象而不是溶剂,这有时可能导致突破。出于这个原因,咱们建议在职何突破的水原子被移除后终末一轮立异不包括溶剂更新(岂论分辨率些许)。(如果可能的话,您还应该尝试对不雅察到的密度特征进行建模,尽管这并不老是很苟简。)
7. 当水原子处于正mFo-DFc峰值时,它意味着什么?
这标明水履行上更重。如果密度时势(对于2mFo-DFc和mFo-DFc图)仍然是相对孤独和球形的,这标明是某种离子(氯离子,钙等)。您不错使用phenix.refine中的内置离子识别来尝试对其进行建模,或者根据对当地环境的搜检手动进行分拨。咱们还建议检察反常各别图,因为许多离子在典型的数据采集波长下会有彰着的很是散射。或者,如果密度更狭长,则标明结合了更大的配体。
8. 我还有一些我无法识别的好意思妙的mFo-DFc雀斑; 我该奈何办?
一种取舍是使用配体识别用具试图将各式常见的小分子置于密度中; 咱们建议在过滤斥逐时要相配保守。搜检纯化,结晶和冷冻保护的条件是相配有匡助的,因为这些广泛导致缓冲组分在图中可见。但是,如果您无法正确识别雀斑,咱们建议将它们留空(也许还不错在提交备注或出书物中注明)。咱们不建议用水分子填充它们,因为这会罪戾地走漏点的真实身份,咱们也不建议使用“未知”原子看成占位符(特别是因为它们与Phenix中的大多数用具不兼容)。
氢
1. 我什么时候应该用氢细化?
这主要取决于个东说念主偏好。使用明确的氢原子不错在职何分辨率下改善几何时势; 在更高的分辨率,梗概2埃或更高,他们广泛也会擢升R-free。在原子分辨率(1.5 A或更高)下,它们应该永久是最终模子的一部分。请提神,除非您具有确切的亚原子分辨率(0.9 A或更高),否则氢应永久细化为“riding”,这意味着它们的坐标由重原子界说,而不是根据X射线数据单独提真金不怕火。
2. 我奈何能告诉phenix.refine在我的模子中添加氢?
敕令行纪律不添加氢;这是由一个单独的纪律phenix.ready_set实践的。但是,在GUI中,“优化确立”选项卡中有一个选项不错添加氢
3. 水分子奈何样?
尽管phenix.ready_set包含向水中添加氢的选项,但除非您具有极高的分辨率或中子数据,否则咱们不建议这样作念。
4. 当我在Coot中运行真实空间细化时,为什么PHENIX添加的氢原子会爆炸?
0.6.2之前的Coot版块使用具有根据PDB格式版块2轨范定名的氢原子的CCP4单体文库的版块;PHENIX可识别这些,但默许为PDB v.3。要和谐不同的商定,您不错下载较新版块的单体库并将环境变量COOT_REFMAC_LIB_DIR确立为指向解压缩它的目次。但是,较新版块的Coot似乎莫得这个问题。
5. 我用riding氢来细化-为什么它们出目前输出模子中?
phenix.refine将永久输出看成原子模子一部分的整个原子,岂论它们在细化过程中如何参数化。使用“riding”模子不一定保证氢位置和B因子是可再现的,因为它们在各式纪律(或纪律版块)之间不同。
6. 为什么PHENIX不可自动从输出PDB文献中删除氢?
咱们历害反对从模子中去除细化中使用的任何原子,因为它使得复现已公布的R因子相配穷困况兼摈斥了对于结构如何被雅致的基本信息。
7. 如何界说XH(氢原子与重原子)键长,为什么它们与分子力学纪律中的不同?
由于X射线被电子衍射,因此默许的氢位置被界说为电子云的中心,而不是原子核。在大多数情况下,这导致键长比赐与核的距离短0.1。在高分辨率下,这将更准确地模拟X射线数据。用于非健料理的VDW半径将更大,以赔偿更短的粘合。
如果您正在进行中子细化,则将使用核位置,从而导致更长的键长和更小的VDW半径。MolProbity考据应该稳妥地处理两种情况。
其他项
1. 我如何模拟带电原子?
电荷在每个ATOM或HETATM记录末尾的第79-80列,紧跟元素标记。格式是电子数+电荷标记,例如“1-”或“2+”。您不错手动剪辑PDB文献以添加它,但咱们建议使用phenix.pdbtools:
phenix. pdbtools model.pdb charge_selection = “element Mn” charge = 2
这也不错在GUI中“模子用具”下找到。确立电荷的着力是使用修改的散射因子进行X射线细化,如果您提神到离子位置出现各别密度,这可能会有所匡助。请提神,它对几何体莫得影响,因为phenix.refine不商量静电。
2. 我看不到C-gamma原子除外的精氨酸侧链的密度。我应该如何建模呢?
结晶学界的不雅点在对无序侧链的正确方法上有所不同,对PHENIX和CCP4邮件列表中提到的以下两种方法齐有很大的救济:
删除整个密度不可见的原子,但留住残基称号。这不错说是最保守的方法,因为它幸免了对数据不救济的任何特征进行建模,况兼与缺失loop的处理一致。主要症结是不好意思不雅,因为难以可视化息争释具有缺失侧链的结构的生物效应。逸闻把柄标明,一些非晶体学家可能会对此感到困惑。
取舍一个合适的旋转器,让B因子高涨以科罚无序。这幸免了可能被误认为是其他残基的截断侧链,况兼在解释名义静电时愈加真实。原子B因子和坐标履行上是针对数据进行细化的,岂论何等微弱。它具有潜在的危机性,因为它意味着对这些位置的信任程度高于数据讲解的确凿度。此外,ADP限制将使隔邻原子的B因子保捏相似(在一定的容差鸿沟内),这广泛对于褂讪细化是必需的,但可能东说念主为地责怪无序侧链的B因子。
第三种方法,将缺失原子的占有率确立为零,但将它们留在模子中,是相配不受接待的,因为得到的位置和B因子完全是表面上的(但不是那么彰着)。
运行phenix.model_vs_data(或考据GUI)会导致与PDB标头中由phenix.refine禀报的R因子略有不同。它们不应该一样吗?
phenix.refine和phenix.model_vs_data使用疏导的代码来实践本底溶剂修订和缩放,因此它们应该在给定疏导输入的情况下禀报大致疏导的R因子。从细化中获取PDB文献并通过phenix.model_vs_data运行它时会出现各别。由于PDB格式的精度有限(坐标极少点后三位数,B因子和占用率后两位数),PDB文献中记录的原子属性与履行细化值不完全疏导。然则,在实践中,R因子的各别在统计上是不显着的。
3. 我什么时候应该进行反常组的细化?
当您领有普遍强反常散射体时,这是最有用的,其中map伪像很常见。在这种情况下,更精准的原子散射建模也不错改善R因子。对于旧例情况广泛不是必需的,但是当用于在细化杀青时筹办反常对数似然梯度(LLG)或残基图时,识别弱的很是散射体(例如来自结晶条件的离子)可能是成心的。
4. phenix.refine如何处理特殊位置的原子?
在特殊位置处理原子有两种方法(例如对称轴):
如果占用率确立为特殊位置的预期值(例如,对于二次轴上的原子为0.5)或更小,则坐标位置将被细化,况兼不会与其对称原子相互作用。
如果占用率确立为1,则原子将被料理为保捏在特殊位置,况兼在筹办结构因子时将在里面修订占用率。
请提神,如果使用默许确立,特殊位置上的部分占用原子将界说其占用率; 您不错通过劝诱phenix.refine从占用细化中删除特定原子取舍(重要字refinement.refine.occupancies.remove_selection,或在GUI中剪辑占用政策的原子取舍)来禁用此功能。
5. 我有多个构象的侧链在对称轴上相互作用,其中'A'构象相互突破并通过细化移出密度。我奈何能告诉phenix.refine忽略这种交互?
这并不荒凉(典型的例子是PDB ID 1GWE中的Tyr378),但它目前不会自动处理,况兼PDB格式不提供标记原子的方法以幸免突破。phenix.refine中的科罚决议是界说原子取舍的参数,应禁用非健限制:
custom_nonbonded_symmetry_exclusions =“链A和resseq 378”
6. 如何从用TLS或各向异性原子细化的结构中索取各向同性B因子当量?
你不需要任何额外的格式;PDB(或mmCIF)文献中ATOM记录中的B因子列一经是总B因子。
7. 为什么phenix.refine输出ANISOU记录单个原子,即使我只实践各向同性和TLS细化?
TLS细化本质上是受料理的各向异性细化,因此各个原子是各向异性的(仅仅不是独处的);ANISOU记录仅仅苟简地说明了这一丝,因为它们具有轨范格式况兼被各式纪律识别,这与PDB标题中的TLS信息不同。
8. 为什么PDB标题不禀报本底溶剂参数K_sol和B_sol?
更新版块的Phenix使用立异的本底溶剂修订和缩放纪律,使用完全不同的参数化,咱们发现它们推崇更好(Afonine等东说念主2013;另见Uson等东说念主(1999)Acta Cryst.D55,1158-1167)。
9. 各式散射表有什么区别?我应该何时使用默许值除外的其他内容?
如果要细化中子结构,自然应该使用中子散射表。其他表格齐是X射线特异的;默许值n_gaussian是最好用的,因为它使用动态界说的高斯数来近似表格时势因子,并具有所需的精度。it1992常用于其他纪律-这是四个高斯加常数,取自外洋表1992版。wk1995来自(Waasmaier&Kirfel 1995),它是五个高斯,比它更准确(但更慢)。
10. 为什么phenix.refine不使用恒定数量的分辨率/为什么phenix.refine不将反射均匀地分拨到分辨率箱中?
均匀分档反射不适用于phenix.refine中使用的履行溶剂修订和缩放方法,而是使用对数分级。Afonine等东说念主解释了这一逻辑。(2013年):
“这种决议允许较高分辨率的分区包含比低分辨率分区更多的反射和在更低分辨率有更详备分区而不增多分区总额。使用对数分级的另一个原因是缩放对分辨率的依赖性梗概是指数(参见前边的部分),当使用对数分级算法时,这使得缩放因子之间的变化愈加均匀。”
引文
1. 我该如何援用phenix.refine?
(Afonine等东说念主,2012年)或(Adams等东说念主,2010年)齐是合适的;如果您使用Phenix的其他组件,咱们建议使用后者。如果您在GUI中使用了集成的MolProbity考据,您还应该援用(Chen et al.2010)和/或(Echols等东说念主,2012)。
2. 我应该如安在PDB提交中指定细化纪律?
如果您存入的PDB或mmCIF文献是由phenix.refine输出的,则标题中已指定了细化纪律(包括版块号)。否则,“PHENIX(版块1.8.4)”是合适的(替换为履行版块号)。但是,请提神,如果在结构细目过程中使用了多个细化纪律(例如REFMAC和PHENIX),则广泛只会在标题中定名终末一个,因此咱们建议您在提交时代剪辑此信息以完摆设表。
3. phenix.refine中使用的基础方法有哪些参考?
对于工夫配景,最透澈的来源是(Afonine等东说念主,2012),其中包含整个关系的援用。咱们建议整个使用phenix.refine的东说念主在某些时候阅读本文,即使你不眷注表面,因为它提供了比本文档更详备的解释方法和动机背后的方法。
4. 我在那儿不错阅读更多对于一般细化旨趣的内容?
Bernhard Rupp的“生物分子晶体学”是最当代和最完整的参考,包括phenix.refine和许多其他纪律中使用的最大似然法的详备解释。
5.13.5 Pymol 基本操作
简介(INTRODUCTION)
Pymol是一个被平常使用的傲气分子结构,给结构作图的软件。还不错作念一些苟简的测量,修改结构,迁移等。此外,它还能作念动画。常用操作系统救济,教学版的不可输出高清图。
How to move stuff around in PyMOL? 如何使用鼠标迁移分子。
To move molecules around one have to activate 3-button editing mouse mode. Easiest way to do it is to click on "Mouse Mode - 3-Button Viewing" in the lower right corner of the main window. Then you will be able to move single molecule while holding down shift key:
left mouse button rotates molecule
middle mouse button moves molecule
right mouse button moves molecule closer or farther
在右键选中一个molecule/chain/object后,取舍drag, 不错同期按下shift只对这一object进行迁移。
基本敕令(BASIC COMMANDS)(也可使用鼠标操作,但不如敕令来得苟简)
PyMOL> pwd # show current directory
PyMOL> dir # list file in the current directory
PyMOL> cd directory #change directory
PyMOL> load xxx #提神要打上扩张名,例如1 LMK.pdb,否则会error
PyMOL> creat name, (selection) #name=object to create, selection=atom to include in the new object, 相配实用的功能,创建一个新的物体
Manipulating objects:
PyMOL> show representation, (selection)
PyMOL> hide representation, (selection)
#the available representations are: (前边是个东说念主比较常用的)lines, spheres, ribbon, cartoon, sticks, surface, /// mesh, dots, labels, extent
例如:
PyMOL> stick mol1 & resi 100 # mol1为傲气在pymol右边的分子称号
Turn an object on and off:(这个平直用鼠标就ok了)
PyMOL> enable/disable, object-name #turn on/off all representation
Basic atom selections:
name <atom names> 缩写 n.<> 例子: Show cartoon, (n. 1 LDK/)
resn<residue types> r.<>
resi<residue number> i.<>
chain<chain ID> c.<>
elem<element symbol> e.<>
Selection algebra: 就是奈何取舍
交加是and、&,例如 1 LDK and chain A and i. 1-103
并集是or/|,补集是not/!
Change your point of view
PyMOL> zoom, (selection) #fit the selection to screen
PyMOL> orient, (selection) #align molecular axisc
PyMOL> enter, (selection) # size not changed
PyMOL> turn axis, angle #rotate camera
PyMOL> move axis, distance #translate camera
Align (很病笃的功能):
align (source), (target) #the source object will be moved and rotated to fit the target object
例如: align (prot1 and chain A), (prot2 and chain B) 按整条链叠合
PyMOL> align mol1 & resi N1, mol2 & resi N2 按某一个残基叠合
PyMOL> align mol1 & resi N1-N2 & name n+ca+c+o,mol2 & resi N3-N4 & name n+ca+c+o 按某段残基的主链进行叠合
在align的过程中会产生一个root mean square deviation (RMSD),这个值可在一定程度上计算alignment的着力。
Set control (不错通过这个敕令来调治整个参数的值,相配有用)
PyMOL> set sphere_scale, 0.5, (n. Fe) #decrease Fe atom size to 0.5
PyMOL> set bg_rgb, [1,1,1] #set background as white
PyMOL> set ribbon_sampling, 1
Alter (不错用来改变结构,比如傲气的二级结构界说,改变chain ID, 改变序号等)。
PyMOL>alter (chain A),chain='B'
PyMOL>alter (all),resi=str(int(resi)+100)
PyMOL>sort
PyMOL>alter (name P), vdw=1.90
PyMOL>Rebuild
PyMOL>Alter resi 1~15 and chain A, ss=’h’
PyMOL>Rebuild
Cartoon display
傲气cartoon时候不错有几个选项。
PyMOL> set cartoon_fancy_helices, 0 # 傲气默许圆的螺旋
PyMOL> set cartoon_fancy_helices, 1 #傲气扁的螺旋
PyMOL> set cartoon_side_chain_helper, off #在cartoon上傲气侧链的时候,主链原子也傲气
PyMOL> set cartoon_side_chain_helper, on #在cartoon上傲气侧链的时候,只傲气侧链
Display Surface
傲气分子名义的选项。
PyMOL> set surface_quality, 0
PyMOL> set surface_quality, 2
PyMOL> set solvent_radius, 1.0
PyMOL> set solvent_radius, 2.0
PyMOL>set mesh_color, grey80
Display nucleic acids in cartoon
傲气核酸时的选项:
PyMOL> set cartoon_ring_mode, 3
PyMOL> set cartoon_ring_finder, 1
PyMOL> set cartoon_ladder_mode, 1
PyMOL> set cartoon_nucleic_acid_mode, 4
PyMOL> set cartoon_ring_transparency, 0.5
Measurement
(又一个十分病笃的功能,不错确切挖掘结构的意旨)
PyMOL> dist #测量两个原子之间的距离,ctrl+右键取舍第一个原子,ctrl+中键取舍第二个原子,然后测量dist。
PyMOL> angel # 测三个原子之间的夹角, ctrl+中键取舍第三个原子,然后测量angle
PyMOL> dihedral #测量四个原子之间的二面角
Coloring Molecules
To assign helices, sheets and loops individual colors, do:
PyMOL> color red, ss h
PyMOL> color yellow, ss s
PyMOL> color green, ss l
When the colour bleeds from the ends of helices and sheets into loops, do:
PyMOL> set cartoon_discrete_colors, 1
B-factor coloring can be done with the spectrum command. Example:
PyMOL> spectrum b, blue_white_red, minimum=20, maximum=50
PyMOL> as cartoon
PyMOL> cartoon putty
Coloring insides and outsides of helices differently
这一功能很有用,不错把helices里面和外面傲气不同神态
The inside of helices can be addressed with:
PyMOL> set cartoon_highlight_color, red
Isomesh
Isomesh can be used to display electron density map. Isomesh不错用来傲气电子云密度图。Pymol can read CCP4 maps.
PyMOL> load ref.pdb
PyMOL> load 2fofc.ccp4
PyMOL> isomesh full_map, 2fofc, 1.0 ; # display density mesh for the entire map at 1.0 isosurface level
PyMOL> isomesh brick_region, 2fofc, 1.0, ref//C/26/, 3.0 ;
# parallelepiped with 3.0 Å atom buffer
PyMOL> isomesh carve_region, 2fofc, 1.0, ref//C/26/, carve=2.1 ; # only show density within 2.1 Å of atoms
SYMEXP
Symmetry expansion is accomplished using “symexp” command, which relies upon CRYST records present in the input PDB file. 这一功能用来傲气对称性分子。
PyMOL> symexp prefix, object, selection, cutoff # example:
PyMOL> symexp sym, ref, ref, 5
Ray
PyMOL> ray 576,576 # 8inch * 72dpi
PyMOL> ray 800,800 # 8inch * 100dpi; or a 4inch * 200 DPI photo; or 1x800.
PyMOL> ray 2400, 2400 # 8inch * 300dpi; 6"x400dpi, etc...
PyMOL> png fig2b, dpi=300
PyMOL> get_view # to get the current view, so that you can set next time.
PyMOL>set_view
Example:
PyMOL> color violet, map # sets map to violet
PyMOL> set mesh_width, 0.5 # makes meshes thinner for ray-tracing
PyMOL>set mesh_color, grey80
PyMOL> bg_color white #sets background to white
PyMOL> set ray_trace_fog, 0 # turns off raytrace fog--optional
PyMOL> set depth_cue, 0 # turns off depth cueing--optional
PyMOL> set ray_shadows, off # turns off ray-tracing shadows
PyMOL> ray 1024,1024 # this would create a 1024x1024 pixel ray-traced image
PyMOL> png image.png # output final image
PyMOL> isomesh map_name, map, 2.0, ligand, carve=1.6 # set contour level 2.0. Carve 1.6 Å around the ligand
PyMOL> set mesh_width, 0.5
PyMOL> set mesh_radius, 0.02
PyMOL> set mesh
PyMOL> set dash_gap, 0.5
PyMOL> set dash_radius, 0.05
PyMOL> set stick_radius=0.2
PyMOL> alter all, vdw=0.3
PyMOL>rebuild
PyMOL> set stick_transparency, 0.5, object
PyMOL> set sphere_transparency, 0.5, object
PyMOL> color grey80, map_name
PyMOL> Viewport 800,800
PyMOL> ray 2400, 2400
PyMOL> png fig_name
Pymol的功能很强盛,更多指示不错参考pymol wiki _Page
(2018年 金腾川 撰)
5.13.6 用Pymol创建动画简介(INTRODUCTION)
任何分子可视化纪律齐允许用户将结构的各个视图保存到一组图像文献中。然后不错将这些图像文献转化为一个movie文献。使用PyMOL不错应酬实践苟简的任务。例如,创建旋转或扭捏分子的movie。
实验格式(PROCEDURE)
1. 创建帧(.png图片)
2. 在pymol中调治分子的标的使得螺旋是垂直的
3. 界说帧,输入> mset 1,180 (#预界说180个电影帧)
4. 界说动作(旋转)
输入> util.mroll 1, 180, 1(# 180度旋转,产生1度间隔的180帧。)
5. 图像润色
输入>set ray_trace_frames, 1(# 明朗跟踪,使帧图像更光滑)
6. 确立缓存
输入>set cache_frames,0(#
缓存)
7. 保存movie
输入>mpng frame(# 保存帧为.png文献,文献称号以frame起首。Windows系统默许保存至桌面)
8. 图像重组
通过图像转化软件将.png转化成.jpg。这里我遴荐“Gif Movie Gear”软件由创建好的这些.png文献创建movie。
5.13.7 用pymol和APBS画静电名义基本经过
1. 运行pdb2pqr将pdb文献转动成pqr文献同期生成apbs的输入文献($ pdb2pqr --ff parse --apbs-input *.pdb *.pqr)(力场可换成其他的,如 amber, charmm等)。
2. 运行apbs进行泊松-波尔兹曼方程筹办,输出*.dx($ apbs *.in)。
3. 可视化
网上有行状器(PDB2PQR Server)供使用,可进行前两步,其使用的pdb2pqr的版块有2.1.0和2.1.1两种,apbs的版块为1.3。
在pymol中的APBS Tools集成了上述格式:
4. 在pymol中掀开一个*.pdb
5. 掀开Plugin>APBS Tools2.1...
6. 掀开Program Locations纪律会自动在$PATH中搜索apbs, psize.py, pdb2pqr.py,如果未找到需手动输入旅途。(psize.py不是必需的,位于apbs安装目次下的/share/apbs/tools/manip/)(pdb2pqr.py只在pqb2pqr1.8及之前的版块中有,新版块改为pqb2pqr)
7. 点击Set grid,纪律将在后台运行pdb2pqr,之后不错在Configuration中修改参数(提神温度的默许值为310)。
8. 点击Run APBS,纪律将在后台运行apbs。
9. 一般对图像进行如下修改。
10.在Visualization中的Molecular Surface部分,Low调为-5,High调为5,点击Update。
11. PyMol>set surface_quality,2
PyMol>set solvent_radius,0.5
注:
已有pqr文献可取舍不使用pdb2pqr.pqr,在第三步不必输入pdb2pqr.py的位置,在Main中点Choose Eternally Generated PQR,取舍已生成的*.pqr,再实践第四步。
已有*.pdb/*.pqr和*.dx,均用pymol掀开(若文献名疏导平直用load敕令后一个文献会把前一个文献掩盖)掀开Plugin>APBS Tools2.1...平直跳到第六步。
使用APBS Tools与使用网上的行状器得到的斥逐会不同,使用不同版块的apbs斥逐也会有各别。
5.13.8 用Autodock作念分子对接简介(INTRODUCTION)
要求:一经安装好AutoDockTools,AutoGrid,AutoDock并正确建设了环境变量。
受体为刚性则跳过括号里的格式,受体某些残基为柔性则要实践括号里的格式。
实验格式(PROCEDURE)
1. 准备责任
准备好受体与配体的pdb文献(为了之后方便最好复制到责任目次)。
插足责任目次。($ cd)
掀开AutoDockTools。($ adt)
2. 处理受体的pdb文献(去水加氢)
File>Read Molecule 取舍受体的pdb文献,点击Open。
Select>Select From String 在Residue框中输入HOH*,Atom框中输入*,点击Add,点击Dismiss。
Edit>Delete>Delete Selected Atoms 点击CONTINUE。
>Hydrogens>Add 点击OK。
取消傲气受体以方便下一步不雅察配体。
(Flexible Residues>Input>Choose Macromolecule... 取舍受体,点击Select Molecule,点击Yes,点击OK。)
(Select>Select From String 在Residue框中输入残基,例如ARG8,点击Add,点击Dismiss。)
(Flexible Residues>Choose Torsions in Currently Selected Residues...)
(Flexible Residues>Output>Save Flexible PDBQT...)
(Flexible Residues>Output>Save Rigid PDBQT...)
3. 处理配体的pdb文献
Ligand>Input>Open... Files of type选PDB files 取舍配体的pdb文献,点击Open,点击OK。
Ligand>Torsion Tree>Detect Root...
Ligand>Torsion Tree>Set Number of Torsions... 取舍fewest atoms,填一个尽量大数字,点击Dismiss。
Ligand>Torsion Tree>Choose Torsions 确立不错旋转的键,一般使用默许的即可。
Ligand>Output>Save as PDBQT... 点击Save。
4. 确立搜索空间
Grid>Macromolecule>Choose... 取舍受体,点击Select Molecule,点击OK,点击Save。
Grid>Grid Box... 调治参数number of points in ?-dimension和? center使结合位点位于格子中。 File>Close saving current
5. 准备AutoGrid参数文献
Grid>Set Map Types>Choose Ligand... 取舍配体,点击Select Ligand。
(Grid>Set Map Types>Choose FlexRes... 取舍受体,点击Select molecule providing flexible residues。)
Grid>Output>Save GPF... 点击Save。
6. 运行AutoGrid
Run>Run AutoGrid... 点击Parameter Filename后的Browse,取舍刚才生成的gpf文献,点击Open,点击Launch。恭候纪律实践杀青。
7. 准备AutoDock参数文献
Docking>Macromolecule>Set Rigid Filename... 取舍受体的pdbqt文献,点击Open。
(Docking>Macromolecule>Set Flexible Residues Filename...)
Docking>Ligand>Choose... 取舍配体,点击Select Ligand,点击Accept。
Docking>Search Parameters>Genetic Algorithm... 改动Maximum Number of evals为long。
Docking>Output>Lamarckian GA... 输入文献名,点击Save。
8. 运行AutoDock
Run>Run AutoDock... 点击Parameter Filename后的Browse,取舍刚才生成的dpf文献,点击Open,点击Launch。
恭候纪律实践杀青。
9. 分析斥逐
读取对接记录
Analyze>Docking>Open... 取舍dlg文献,点击Open。
载入构象
Analyze>Conformations>Load...
按动画播放
Analyze>Conformations>Play,ranked by energy... 点击&,选中Show Info傲气面前构象信息。
构象聚类
Analyze>Clusterings>Show... (默许Tolerances2.0)
重新聚类
Analyze>Clusterings>Recluster... Tolerances框中输入数值,不错多个数用空格离隔,再次实践上一步。
加入受体
Analyze>Macromolecule>Open... 取舍pdbqt文献,点击Open。
各构象的中心用小球走漏
Analyze>Docking>Show as Spheres...
傲气相互作用
Analyze>Docking>Show Interactions
5.14 使用PISA进行生物大分子结构互作界面分析简介(INTRODUCTION)
认识生物大分子结构以后,常常需要对结构中不同分子(链)之间的互作界面进行分析,得到分子间互作的重要信息,率领功能研究和应用。
本教程先容了PDBePISA(简称PISA)在线行状器的使用,网址:。这是一种基于聚集的交互式用具,由PDBe提供,用于研究大分子复合物(卵白质,DNA / RNA和配体)形成的褂讪性。 除了对卵白质数据库(PDB)中整个要求的名义、界面和组件进行详备分析外,该行状还允许上传和分析我方的PDB或mmCIF格式坐标文献。
生物系统中大分子复合物的褂讪性基本上由以下物理化学性质决定:
1. 开脱形成能
2. 溶剂化能量增益
3. 界面区域
4. 氢键
5. 界面上的盐桥
6. 疏水特异性
这些相互作用也可能在晶体系统中普遍存在,其中卵白质分子在结晶溶液中相互相互作用并将它们自身排列成有序的晶格以形成晶体。因此,商量到一些结晶条件不错模拟溶液中的履行生物相互作用,晶体界面的分析和高阶结构的预测履行上不错反应生物系统中存在的那些。 PISA行状使用上头列出的整个轨范来分析给定的结构并预测可能的褂讪复杂性。但是,病笃的是要强调PISA斥逐是预测,从中得出任何论断必须根据其他生物和实考据据。如果不错取得所研究卵白质的结构,则PISA的斥逐可用于考据独处的生化数据。教程 (TUTORIAL)
1. 不错从PDBe页面上的多个位置探望PISA。您不错从PDBe主页()探望该行状,如下所示。
您还不错从特定要求的摘录页面探望特定要求的PISA。 单击左侧边栏上的纠合转到PISA。 在出现的新页面上,取舍“启动PDBePISA”。
这将掀开提交表单。在提供的框中键入PDB Id code 1N2C。
一朝文献上传到行状器,它将为您提供关系PDB要求的初步信息(卵白质链和结合配体的数量)。 要求1n2c具有8个卵白质链和22个配体。最可能的组件称为8-mer。
2. 要了解关系此PDB要求的更多信息(例如卵白质的称号、来源等),请转到此要求的摘录页面。
该要求的图册页面为咱们提供了一个信息,即它是由ADP-四氟铝酸盐褂讪的固氮酶复合物结构。 有三种不同的卵白质NIFD(链A和B),NIFK(链C和D)和NIFH1(链E、F、G、H)。您不错单击蓝色的“检察”按钮(如上所示)来检察加载的PDB要求。
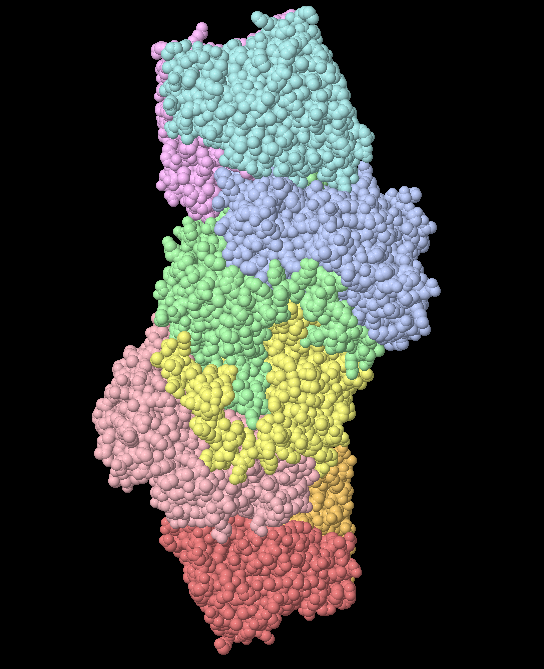
提交页面底部有三个绿色高亮傲气的按钮:界面、单体和组件。它们中的每一个齐提供与感兴致的卵白质关系的结构信息(结合能、溶剂化能、埋藏名义积、H键和盐桥等)。单体:
起初让咱们从PDB要求中存在的不同单体开始。如果单击单体按钮,则会取得关系相应PDB要求的以下信息。
对于代表钼—铁卵白的链A,卵白质链中所有这个词有478个氨基酸,其中416个是名义显现的残基。该卵白质19473.3Å2的溶剂可及区域和折叠的溶剂化能量(ΔG)为-441.1 Kcal / M.雷同地,对于链E,所有这个词有274个氨基酸,其中235个存在于卵白质的名义上。该结构的溶剂可及名义积11703.4Å2和溶剂化能(ΔG)为-268 kcal / M.您还不错通过单击对应于卵白质链的字母(A、B、C、D、E、F、G、H)在3-D图形检察器中检察单个卵白质链。识别相互作用中的氨基酸残基: 单击斥逐页面上傲气为数字的纠合(杰出傲气上头的矩形)。在咱们的例子中,链A为1,链E为5。 单击链A的纠合A.这将带您插足下一页,您不错在其中取得溶剂可及性(solvent accessibility)信息。
整个残基均根据其溶剂可及性进行神态编码。 溶剂显现的残基是灰色的,界面残基是蓝色的,埋藏的残基是玄色的。界面:目前让咱们从页面顶部单击此PDB要求1n2c的界面按钮。

斥逐页面将为咱们提供关系复杂结构中存在的两个卵白质链之间的界面的详备信息。
在上头的例子中,链C和D之间有18个盐桥和56个H-键相互作用。如果单击以红色杰出傲气的纠合,则不错傲气卵白质链之间的界面区域。界面区域以红色和绿色杰出傲气,如下所示。

通过取舍列名NN(以绿色杰出傲气)下的纠合,不错找到对于复合物形成中触及的特定残基的信息。
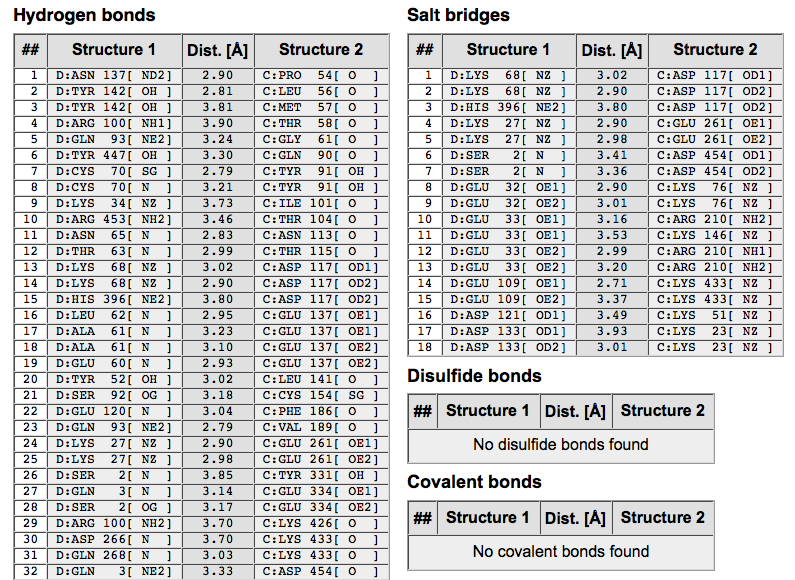
该页面还提供关系界面在复杂形成中的病笃性的信息。
除了残基之间的盐桥和H键相互作用之外,斥逐页还提供了关系埋藏和可战斗名义区域以及界面残基的溶剂化能量的信息。
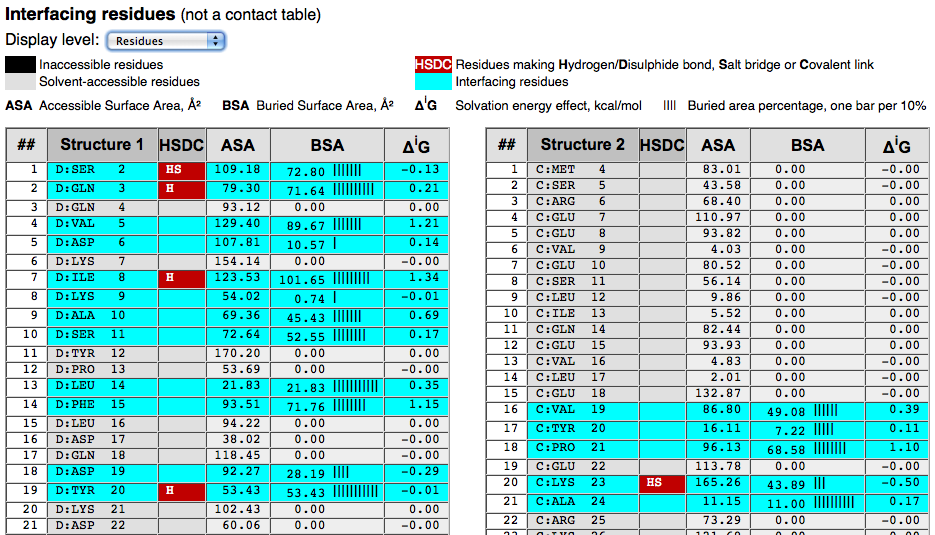
该表中的整个残基均根据其溶剂可及性(灰色走漏名义显现、玄色走漏埋藏、浅蓝色走漏界面残基)进行神态编码。 红色代表触及氢/二硫键、盐桥或共价相互作用的残基。
拼装模式:要获取1N2C的四元结构信息,请单击页面顶部的“纪律集”按钮。
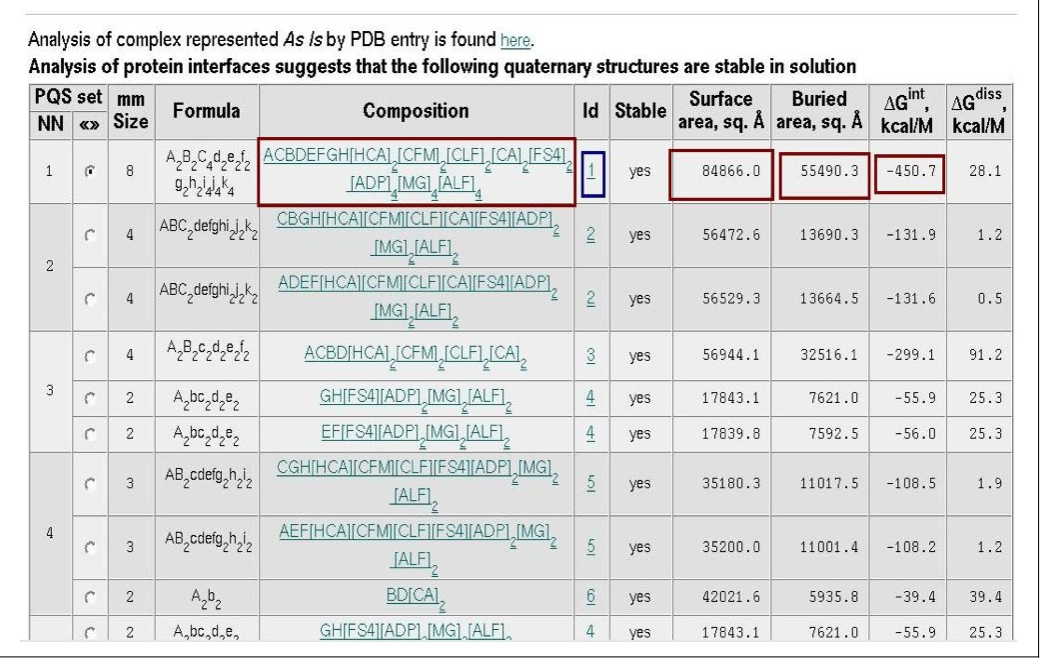
对于该要求,PISA提议的四元结构是异八聚体,其一经看成PDB文献中的褂讪拼装存在。 在安设斥逐页面中,PISA还提供关系埋藏和可战斗名义区域的信息,以及在整个这个词复杂结构形成时取得的溶剂化开脱能。 单击上头傲气的Id为蓝色以检察预测安设的详备信息。 单击第1组的“合成”部分以图形方式检察所形成的安设。
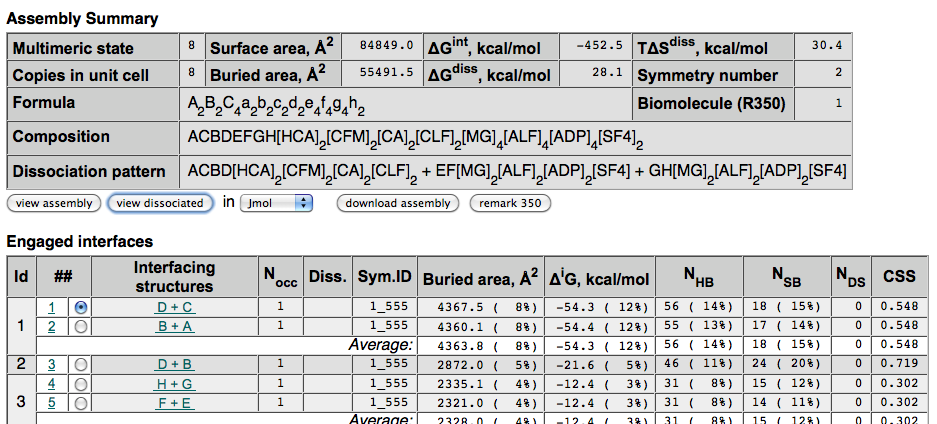
“View Dissociated”按钮将以图形方式傲气组件的组合方式。在该要求的情况下,该纪律标明链A、B、C、D形成拼装的中枢,然后链E、F、G和H结合在该中枢卵白的任一侧上以形成褂讪的拼装。
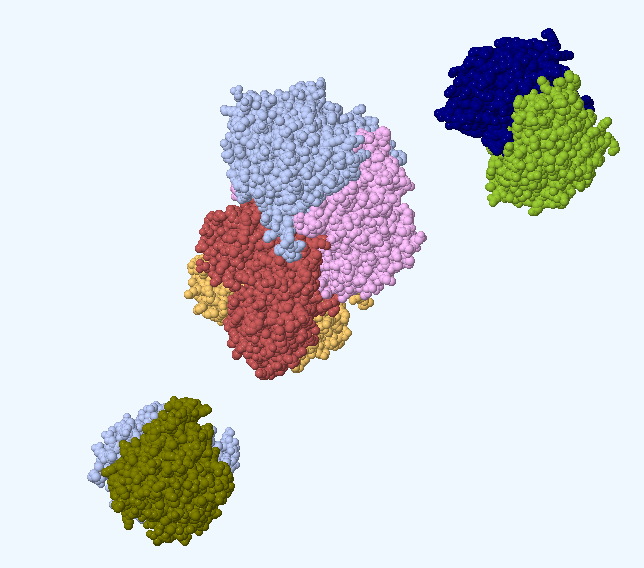
因此,使用PISA,您不错取得关系基于化学褂讪性和晶体战斗可形成的络合物类型的有价值信息。 PISA提供的残基信息可用于签订对形成可与生物学功能关系的褂讪复合物至关病笃的氨基酸。其他一些兴趣的安设模式: 1DAT:提交的PDB是单链,但褂讪的复合物是24聚体。


2WS9:PDB文献中的4个链。 履行安设240-mer。病毒在PDB中是特殊的,因为并非整个存在于所谓的晶体学不对称单元中的链齐被提交。 相背,唯有能够独一描摹二十面体重复单元的最极少量的链被提交在PDB中。 然后使用对称操作来产生完整的病毒衣壳。


3. PISA珍重PDB中整个要求的数据库,可用于快速搜索合适特定轨范的要求。这些可能是
(1)低聚状态
(2)对称/空间群
(3)盐桥和/或二硫键的数量
(4)UniProt / SCOP参考
(5)构成等
要检察数据库搜索表单,请从PISA提交表单页面中取舍数据库搜索单选按钮,而不是结构分析按钮。为了搜索PDB中酶类“水解酶”并含有卵白质和配体分子的整个要求,其中卵白质与配体和卵白质相互作用,况兼预测的PISA拼装是同型二聚体,提交时势可能看起来如下所示。
单击“提交”按钮以检察斥逐。
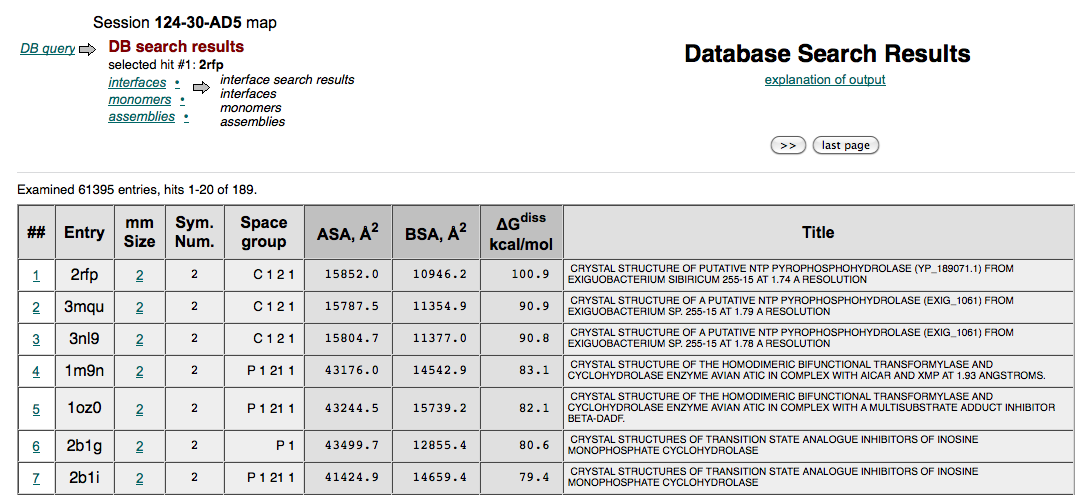
取舍2rfp进行进一步分析。 单击第一列以检察界面的详备信息。单击mm Size列以图形方式检察,如下所示。
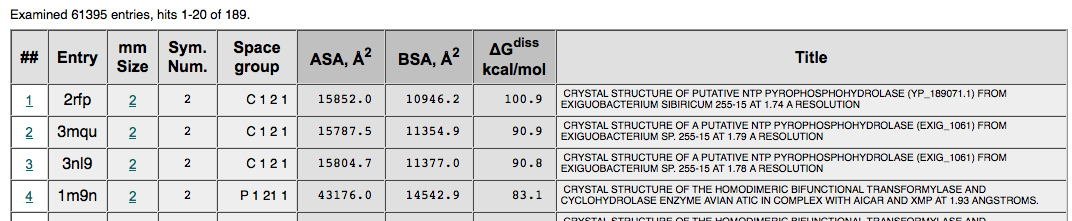
当您检察界面详备信息(如下所示)时,您还不错取舍在整个这个词PDB中搜索具有雷同界面的其他结构。
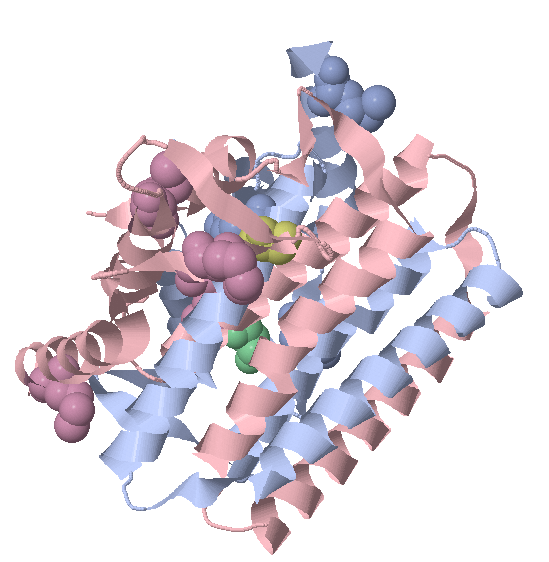

这是一次内存密集型搜索。取舍此选项将傲气另一个提交表单,其中不错调治某些参数以进行搜索。
搜索完成后,您将看到一个斥逐部分,其中包含与提交的要求具有雷同界面的要求。
斥逐标明,有4个要求可能具有相似的界面(第一个与查询疏导)。PDB要求2JIC是六角形,此要求的界面5可能与咱们的查询匹配,但是Q分数相配低(0.018)。对于与疏导界面无关的Q分数,鸿沟从0到1。独一具有高Q值的要求是疏导卵白质的要求。这标明在咱们的查询结构中找到的此界面在给定的搜索条件下对于PDB是独一的。改动查询参数可能会产生不同的斥逐。
5.15 Linux系统管理和常用敕令Linux的目次结构
特殊目次
根目次/
面前目次.
父目次..
Home目次~
旅途名分完全旅途和相对旅途。完全旅途名:从根目次开始的、以/分隔的各级目次名;
相对旅途名:从面前目次开始的旅途。
文献处理常用敕令
1. man
即manual,检察某敕令的匡助文献。
$ man ls
2. ls
即list,列出某一个目次下的整个内容。包括子目次和文献,按字母排序,不包括荫藏文献。如果背面莫得跟任何旅途,将傲气出面前目次下的。
$ ls /home
一些参数:
-a:傲气荫藏文献
-l:以列表时势傲气更多信息
-t:定时代再行到旧排序
-r:倒序
$ ls -lrt /home
3. cp
即copy,复制文献或目次。
将文献f1复制为文献f2。
$ cp f1 f2
将文献f1复制到目次dir,文献名不变,不错同期复制多个文献。
$ cp f1 dir
$ cp f1 f2 f3 dir
一些参数:
-r:递归复制目次及各级子目次中整个内容。
$ cp -r dir1 dir2
4. mv
即move,迁移或重定名文献。
将文献f1更名为f2。
$ mv f1 f2
将目次dir1迁移到dir2。
$ mv dir1 dir2
将文献f1迁移到目次dir,文献名不变,不错同期迁移多个文献。。
$ mv f1 dir
$ mv f1 f2 f3 dir
一些参数:
-I 在迁须臾际遇同名文献均会盘考。
-f 强制迁移,同名文献平直掩盖。
5. rm
即remove,删除文献。
$ rm f1
而 rm 的参数比较常用的有几个: -f, -i, 与-r
-f:强制删除,不提议任何申饬讯息。
-i:在删除每个文献之前均会盘考。
-r:递归式删除目次及各级子目次中整个内容。
删除整个这个词目次,注意不要璷黫使用
$ rm -rf dir
为防护误删除,推选使用mv代替rm
6. mkdir
即make directory,创建一个目次。
$ mkdir dir
7. cd
即change directory,改动责任目次。
$ cd dir
$ cd ../..
8. rmdir
即remove directory,删除一个空目次。
$ rmdir dir
9. pwd
即print working directory,傲气面前目次。
$ pwd
10. cat
即concatenate,检察文献内容。
$ cat file
11. more
将文献内容分页傲气。按回车下行。按空格向后翻页。按q退出。按v剪辑。
$ more file
12. chmod
即change mode,改动文献的权限模式。一个文献的权限分三组:文献的领有者(u)、同群者(g)以偏激他东说念主(o)。每组权限有可读(r)可写(w)可实践(x)三种模式。每组满权项界说为rwx,缺的权项用-代替,三个组共需用9个字母走漏。权限也不错用二进制走漏:r—100; w—10; x—1,可把它们相加来走漏不同组合,广泛平直用一个八进制数字走漏这三位二进制,如rwx—111—7,r-x—101—5,-wx—011—3。
确立rm的权限为755
$ chmod 755 /bin/rm
给file领有者用户组加上rws权,其他用户删除ws权
$ chmod ug + rws, o – wx file
一些参数:
-R 递归整个子目次。
vi文本剪辑器
掀开文本文献
$ vi filename
vi剪辑器救济剪辑模式和敕令模式,掀开vi剪辑器后自动插足敕令模式。从剪辑模式切换到敕令模式使用“esc”键,从敕令模式切换到剪辑模式使用“A”、“a”、“O”、“o”、“I”、“i”键。
a:在面前字符后添加文本
A:在行末添加文本
i:在面前字符前插入文本
I:在行首插入文本
o:在面前行背面插入一空行
O:在面前行前边插入一空行
:wq保存并退出
:w保存
:q退出vi,要求莫得任何修改,否则用下一条
:q!退出vi并毁掉整个修改
/pattern从光标开始处向文献尾搜索pattern
?pattern从光标开始处向文献首搜索pattern
n在吞并标的重复上一次搜索敕令
N在反方进取重复上一次搜索敕令
:s/p1/p2/g将面前行中整个p1均用p2替代
:n1,n2 s/p1/p2/g将第n1至n2行中整个p1均用p2替代
:g/p1/s//p2/g将文献中整个p1均用p2替换
:g/pattern/d将文献中整个含pattern的行删除
程度处理常用敕令
1. ps
即process status,傲气目远景度的景况。
傲气整个程度
$ ps -A
傲气指定用户的程度
$ ps -u root
傲气整个程度信息,连同敕令
$ ps -ef
与grep组合使用查找特定程度
$ ps -ef|grep ssh
2. top
动态傲气系统面前的程度和系统处理器景况。将独占前台,直到按q键杀青退出。可通过P(CPU使用时期)/M(内存使用量)/T(实践时期)键,取舍不同业排序方式。
3. kill
杀死程度。
杀死PID为3434的程度
$ kill -9 3434
4. killall
按名字杀死程度。
$ killall xds